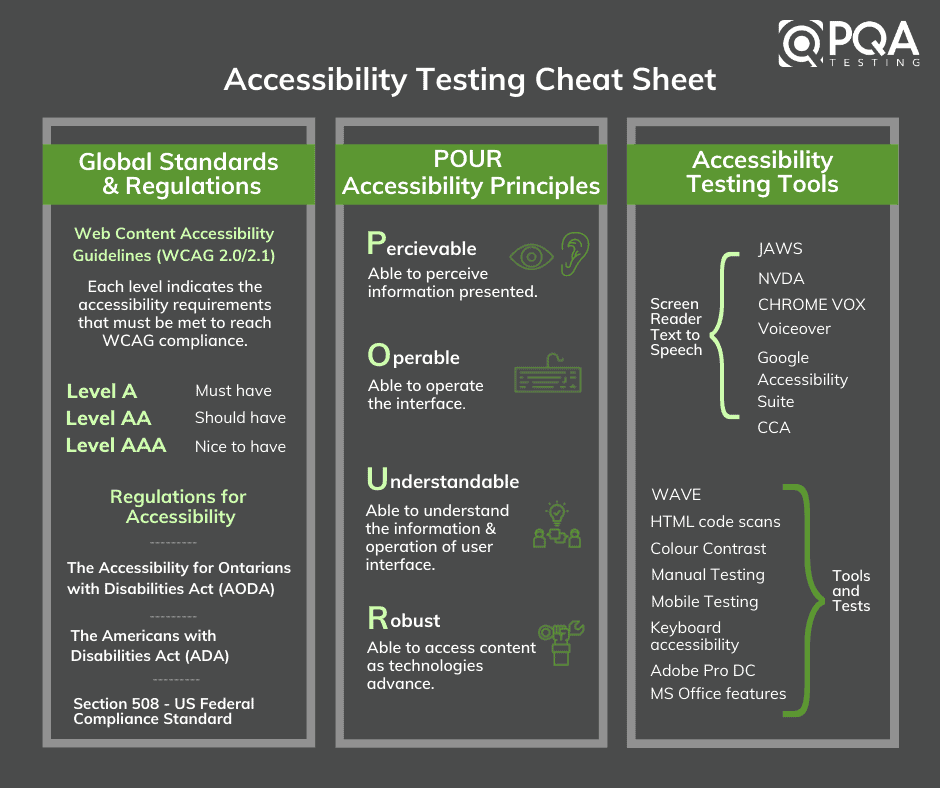
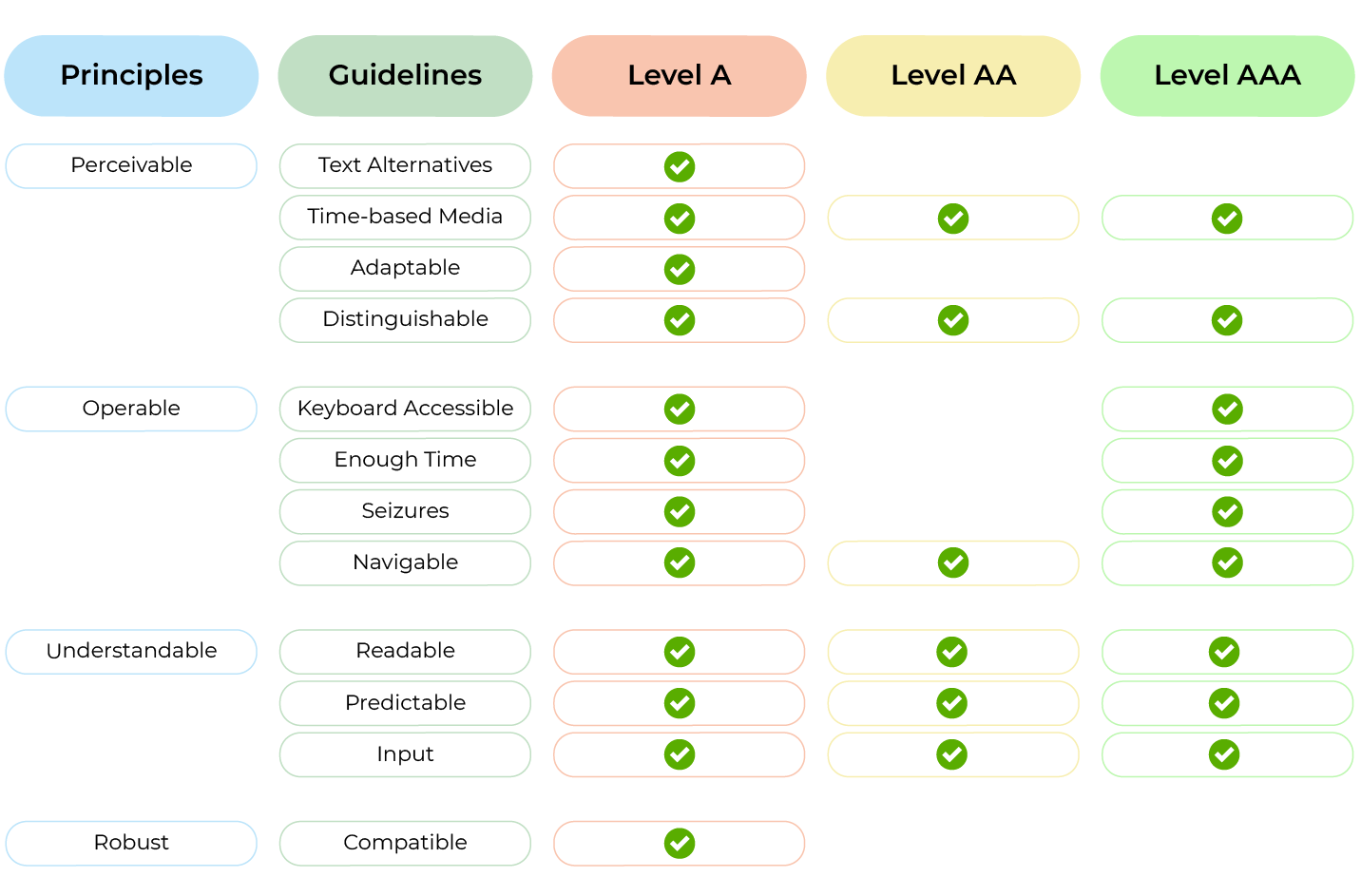
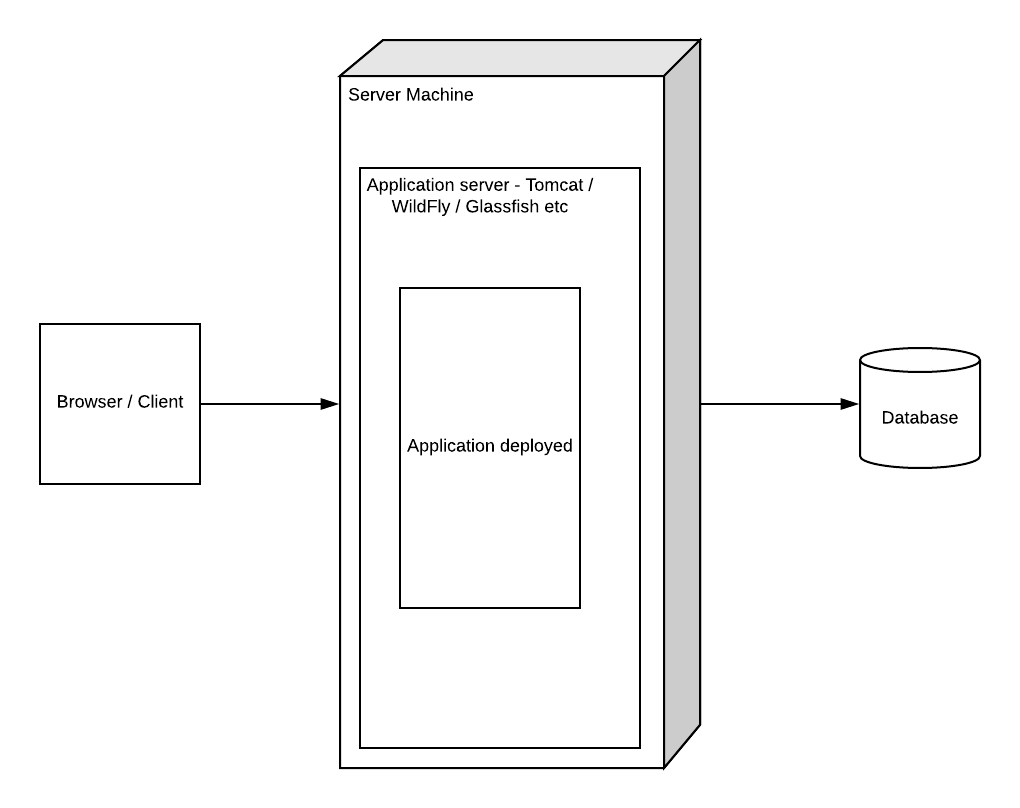
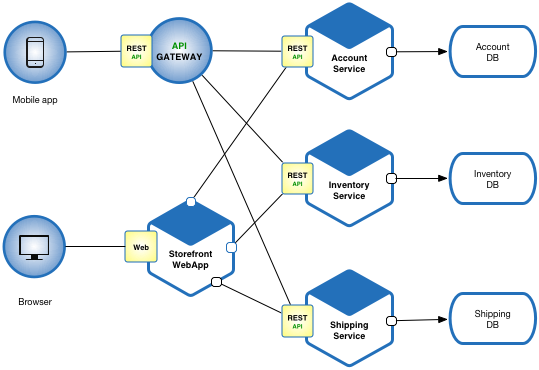
In the previous post, I talked about the benefits of microservices. but the discussion will be incomplete without talking about some of the important challenges one should expect when going for microservices-based architecture.
Well, microservices provide a lot of benefits, but this definitely is not a silver bullet, and if not architected properly, the design can cause more pain than it will provide benefits. Here are some of the considerations one needs to keep in mind when designing an application with microservices.
Too few/ too many services: The first question one needs to deal with when going for microservices-based architecture is how to break the application into microservices. Too many microservices would mean you are unnecessarily complicating the system and too few would mean you are not getting the benefits of a microservice-based design.
Complex DevOps: Unlike a monolith application where you are deploying just a single application, not you are dealing with dozens of microservices. Each service needs its own compilation and deployment pipeline, which means independent management and tracking.
Monitoring: As multiple services are communicating with each other to make the application work, a single failure can impact the overall success. Hence it is important to monitor all services, which means a complex dashboarding, alerting, and monitoring system in place to keep a check on all pieces.
Multiple Tech Stacks: One of the advantages we get with microservices is the independence you get in choosing a tech stack for each piece, but too many tech stacks would mean difficult intra-team support and low expertise on technology.
Managing Data: Another challenge with microservice-based design is managing the data. As a rule of thumb, each microservice should manage its own data. But this can get tricky as sometimes microservices need to share data. If not managed properly one can run into a problem of duplicate sources of data or performance issues in fetching data from other services.