
After discussing creational and strutural design patterns, lets go over behavirol design patterns.
Template: allows one to create a template of code or algorithm which will provide guidelines for different implementations.
Strategy Pattern: helps selection of an algorithm at runtime.
Observer: A pattern that helps manage event-based communication (publish-subscribe). Objects being observed notifies observers about the event, which can then take required actions.

Memento: A pattern is used to restore the state of an object to a previous state.
Example: https://www.geeksforgeeks.org/memento-design-pattern/
Chain of Responsibility: At runtime, command objects are selected to execute responsibilities. One common example is FilterChain used with servlets where multiple filter commands are executed on receiving a Request.
The chain-of-responsibility pattern is structurally nearly identical to the decorator pattern, the difference being that for the decorator, all classes handle the request, while for the chain of responsibility, exactly one of the classes in the chain handles the request. This is a strict definition of the Responsibility concept in the GoF book. However, many implementations (such as loggers below, or UI event handling, or servlet filters in Java, etc.) allow several elements in the chain to take responsibility.
https://en.wikipedia.org/wiki/Chain-of-responsibility_pattern
Command Pattern: creates objects that encapsulate actions and parameters
interface Command
{
public void execute();
}
Example: https://www.geeksforgeeks.org/command-pattern/
Iterator: Iterator helps accesses the elements of an object sequentially without exposing its underlying representation.
interface Iterator
{
boolean hasNext();
Object next();
}Example: https://www.geeksforgeeks.org/iterator-pattern/
Interpreter: A pattern that helps you parse and evaluate sentences in a language.
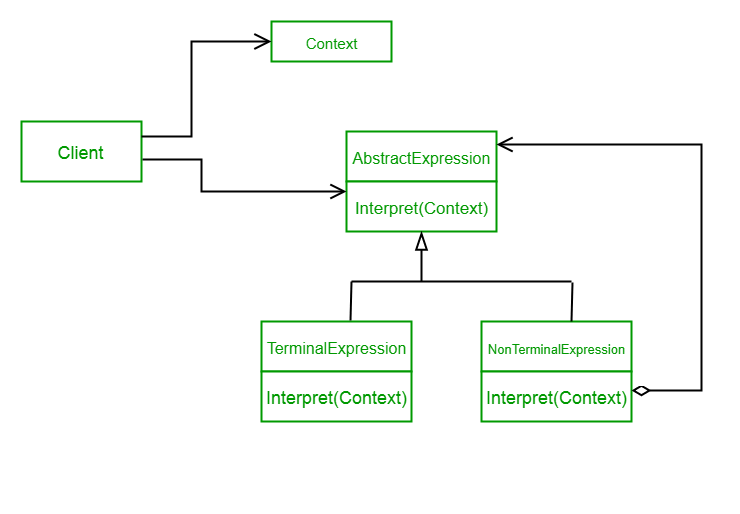
Example: https://www.geeksforgeeks.org/interpreter-design-pattern/
Mediator: Two objects are decoupled as they do not communicate to each other directly, but via a mediator.

Unlike adapter where the communication is one way and caller is aware of provider, in mediator a middle layer helps both parties to communicate.
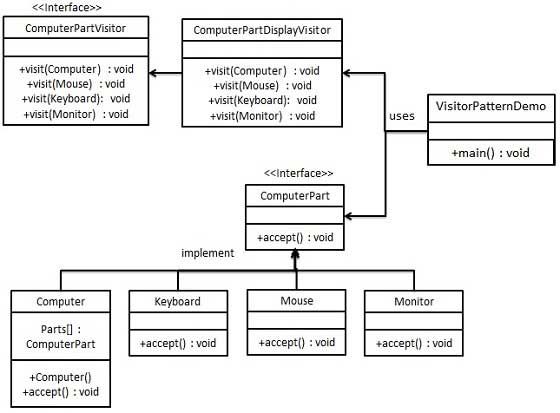
Visitor: Implemented using accept() and visit() methods, the component being visited needs to implement accept method and visiting component implements visit method.
State: An object can manage its behavior based on state. For example, a mobilealert object can have state as ring, silent, vibrate and based on state its bevior is changing. Here is a good example implementation https://www.geeksforgeeks.org/state-design-pattern/

