In the series of exploring designs for popular systems, I will try to come up with Twitter’s system design today.
Functional Requirements
- User should be able to Tweet
- User should be able to follow and view tweets of others on their timeline
- User should be able to search for tweets
- User should be able to view current trends
Non Functional requirements
- Availability
- Performance
- Eventual Consistency
- Scale 150 million users with 500 million tweets per day or ~5500 Tweets/Second
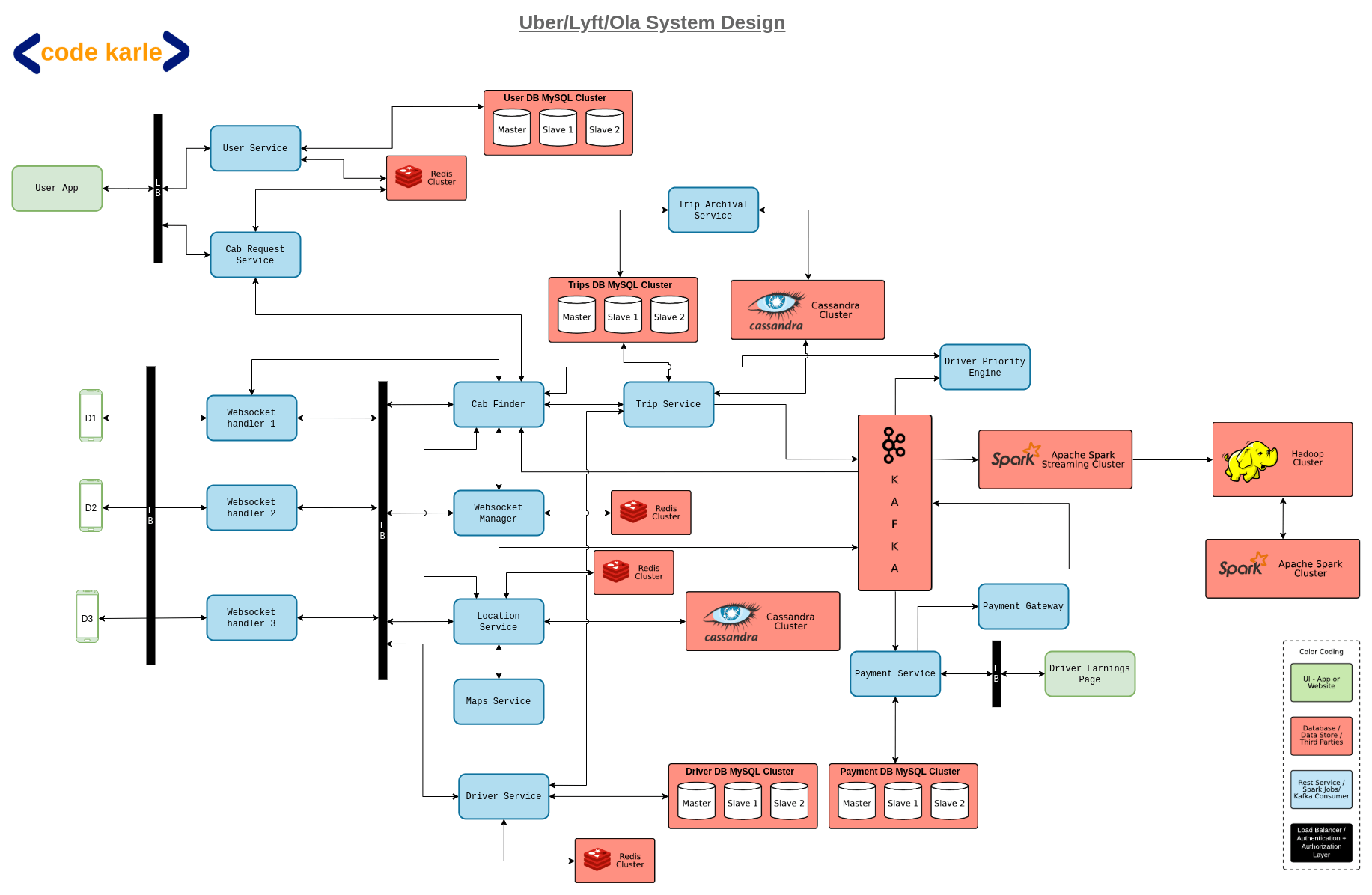
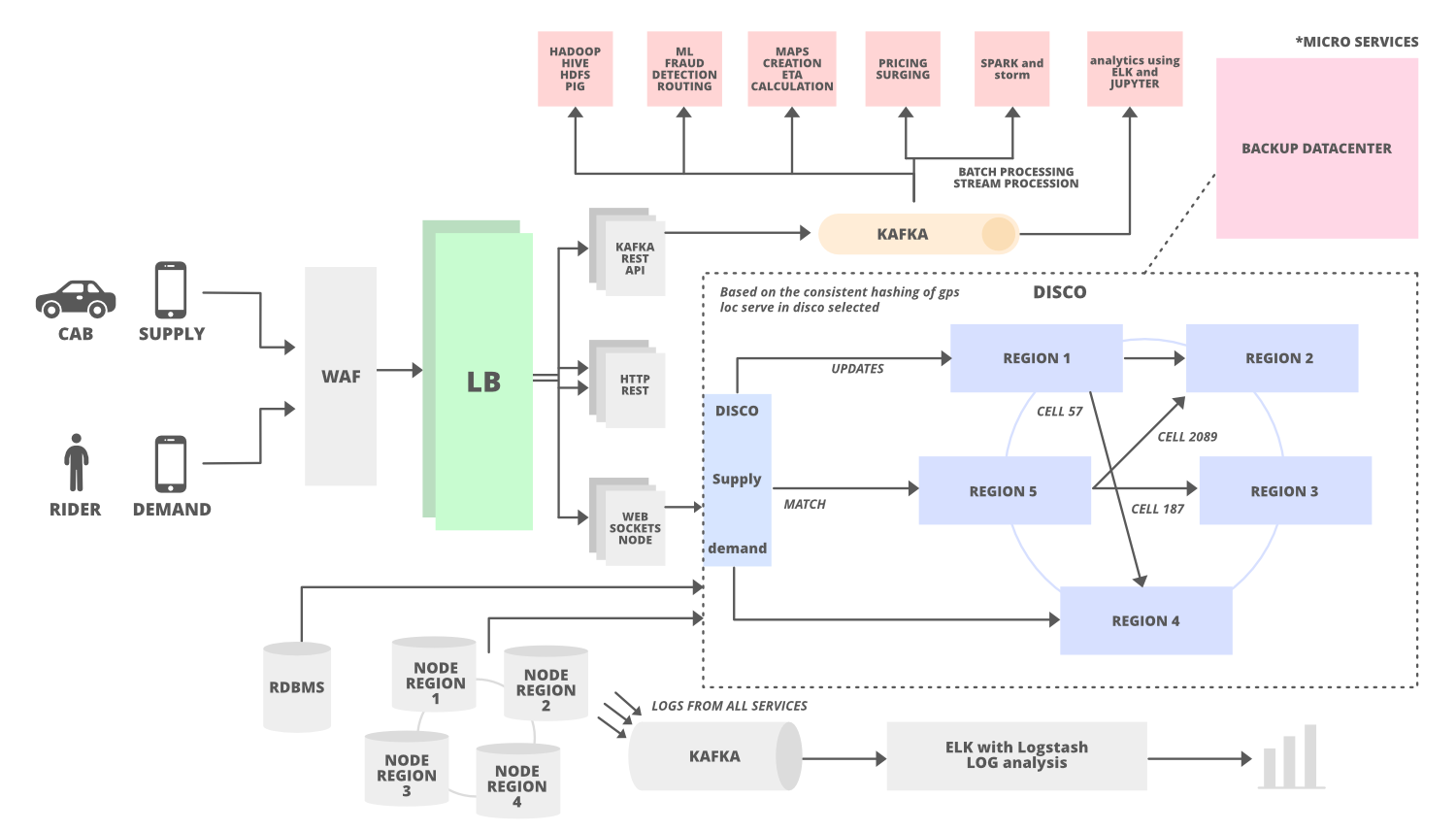
30000 view of Architecture
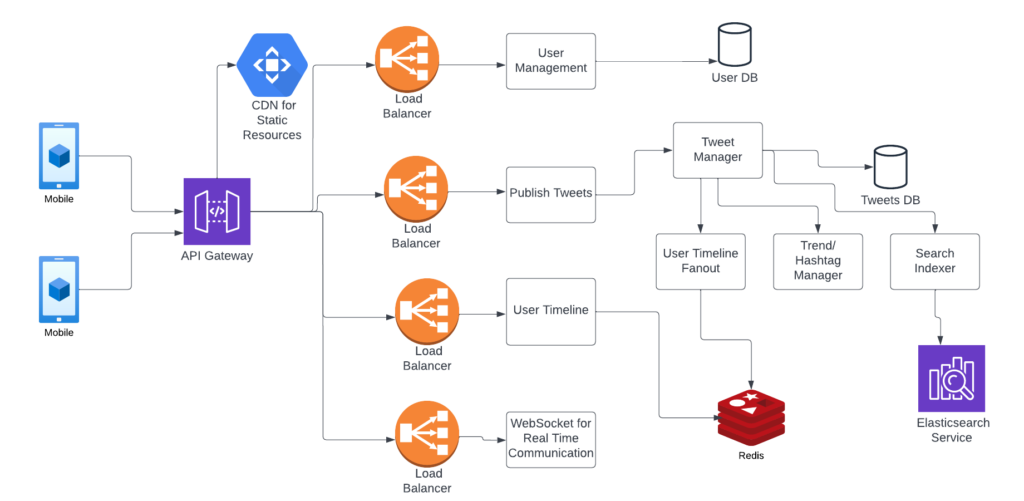
There are one or two aspects of the above design which are very interesting. The first one we can see is the user timeline. This can be a complicated piece, whenever a user login into the app, he should see his timeline, which will show all the tweets from people he is following. The user might be following hundreds of accounts, it will not be feasible to calculate tweets from all these accounts at runtime and create timeline data. So a passive approach makes sense here, where we can keep the user timeline data in a cache beforehand.
Say user A is following user B, and user B publishes a new tweet, at that time itself, user A timeline will be updated with a new timeline getting added to user A timeline data. Similarly, if 100 users are following user B, all the timelines get updated (Fanout the tweet and update all timelines).
It can get tricky if user B has millions of followers. A different approach can be used in this case. Assuming there are not many such popular users, we can create a separate bucket for handling these popular users. Say user A is following user C (celebrity), so instead of updating the timeline for C beforehand, tweets for all such celebrity users can be pulled in real-time.
Another important aspect is hashtagging and trends exploration. For all the tweets coming in, the text can be tokenized and tokens can be analyzed for most usage. For example, when a cricket match is going on in India, many people might tweet with the term match or cricket. Again these trends might be geo-location-based as this particular trend is a country-specific one.