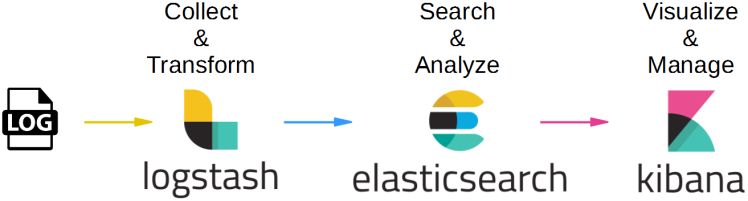
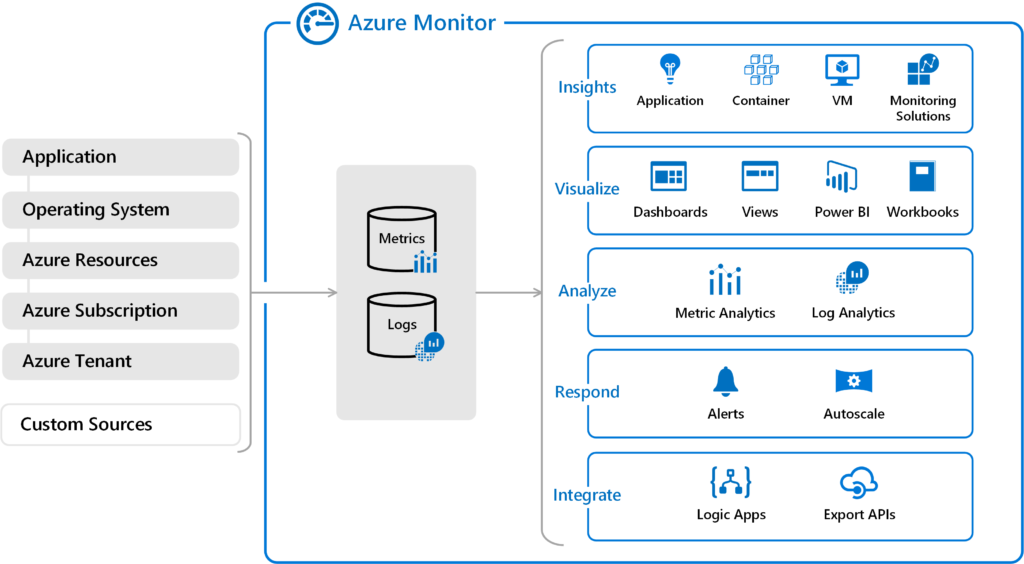
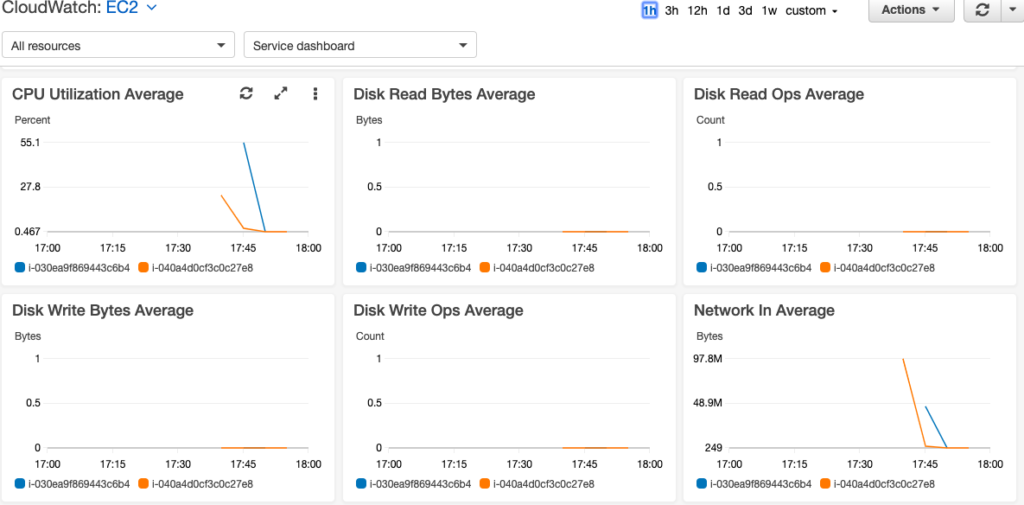
Monitoring logs for an application is an important part of any deployment and support cycle. You want to keep a check on logs to understand what is happening with your application. But these logs are mostly GBs of raw data, that making sense out of this is not very easy. Thankfully there are many off the shelf tools available to help us out in this tedious task. I have already talked about ELK which is a popular tool for log analytics. In this post, we will talk about some of the other popular tools and get an idea of how these can help us.
Splunk is a tool to collect and analyze logs. Splunk basically has three core components, a forwarder which will forward data to Splunk server, An indexer which takes the data and indexes it for better search and finally Search head component which actually looks into the data and searches relevant information. An important aspect of Splunk is that it can easily scale horizontally with Splunk cluster, so you can manage GBs of data coming in the form of logs.
Graylog is another option for log monitoring. You can stream your logs to Greylog, which uses MongoDB and ElasticSearch behind the scenes to make sure you get fast and useful analysis.
Then there are specialized tools like SumoLogic for log analysis, which works on your log data and can provide additional analytics based on your logs. It can help you make sense of your logs as well as provide suggestions.
The list of tools providing log management, monitoring, and analysis tools is increasing by the day as people are recognizing the need and importance of mog monitoring. Here are some additional resources for interested readers.
https://www.dnsstuff.com/free-log-management-tools
https://dzone.com/articles/top-10-log-management-tools-1
https://www.comparitech.com/net-admin/log-management-tools/