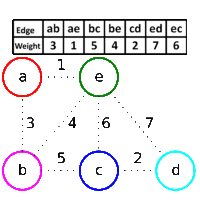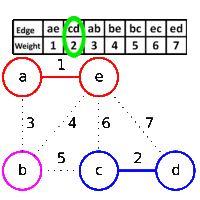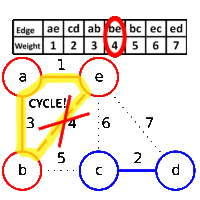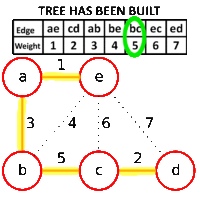
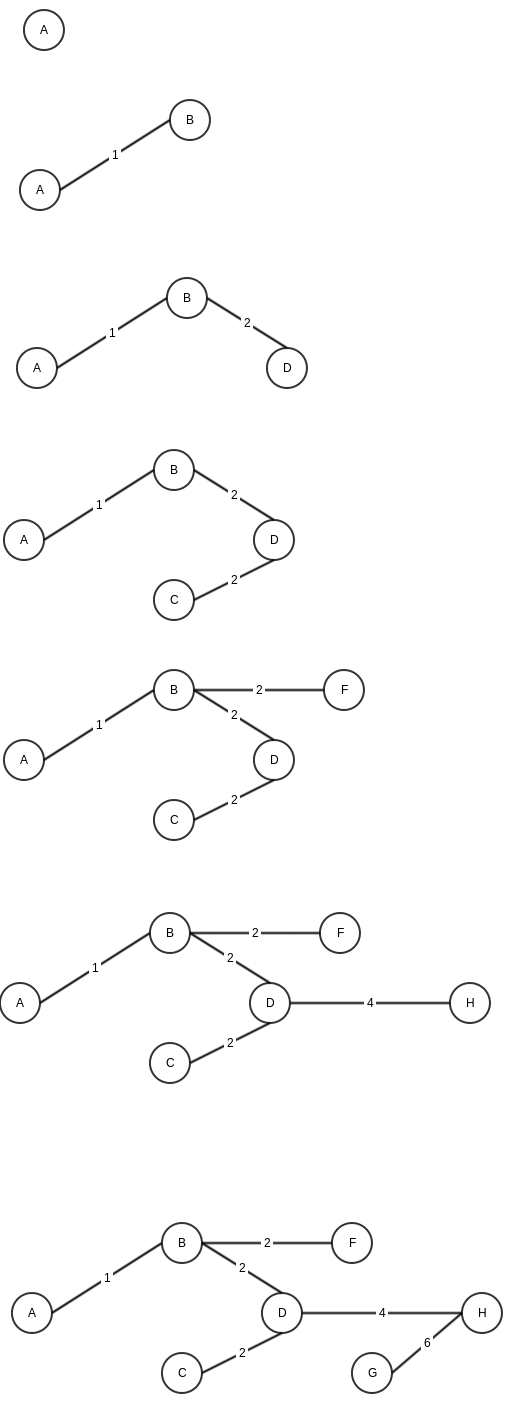
A HashMap is a datastructure which links a key to the value. For example key can be employee id and value might be employee details. The definition actually is true for any map, a hash map adds the functionality of hashing to a simple key-value map. A hash function maps a key to a particular bucket (we can think of it as array position) to add value. For example, if employee id is unique, a good hash function would simply return employee id itself as key. But in case, we are trying to use employee name as key, we might need a better hashing function to generate a bucket id based on employee name.
As we can see from above example, if we do not choose a good hash function, we might not be able to get unique bucket ids for every key. So multiple keys might actually return same bucket id. This causes a collision.
There are 2 important ways to handle collisions
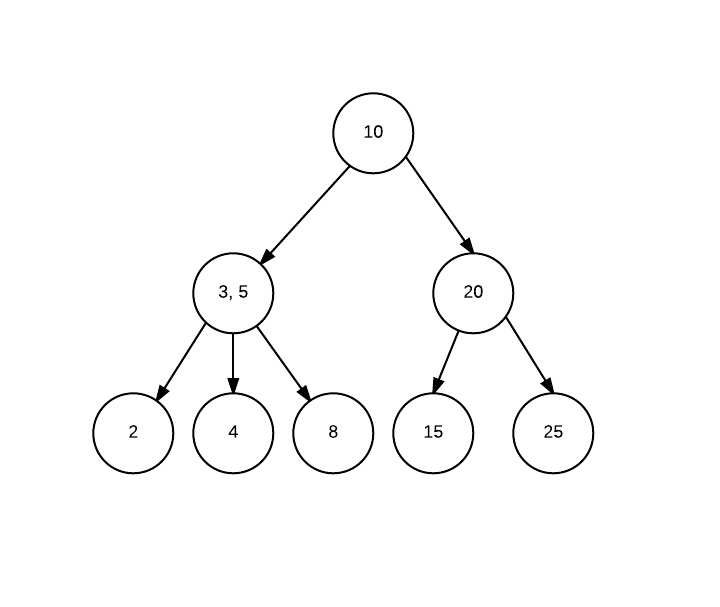
Separate Chaining: In this technique, we create a list inside each bucket to store the objects in case one bucket needs to handle multiple objects. For example, say keys Dave and David returns same hash say bucket number 4 (or array index 4), we would create a linked list in bucket four and store both elements in the list. The advantage is that we can infinitely grow this list (provided no space concerns) and handle any level of collisions.
Open Addressing: In this technique, if in case say two keys generate same hash, the first one would be stored at the hash position, and the other one(s) would be stored at next best position. There are again multiple ways to find the next best position. Here are 2 simple ones
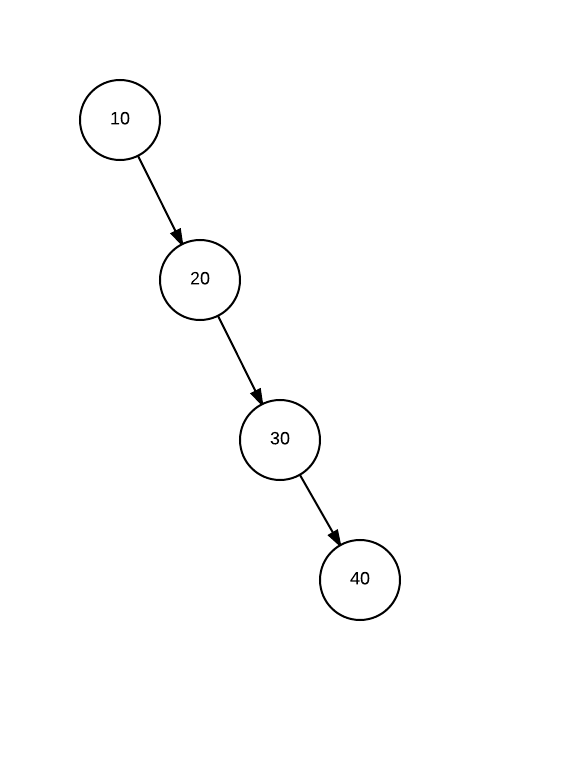
Linear Probing: Simply look for next empty space in array. For previous example, say David has a hash value 4, and we found that position 4 is already filled, we will simply look for next empty position, say 5 is empty, we will save David’s object in 5 or if 5 is also booked we will move on to 6 and so on.
Double Hashing: Going to previous example, if we found bucket 4 is full, instead of simply looking for next empty position, we will invoke a new hash function and add the returned number to initial bucket number. Say input David returned 16 from second hash function, we will try to insert the object at 4+16 i.e. 20th position. If 20th position is also filled, we will move to 20+16 i.e. 36 and so on.
Worst case Analysis
The performance of a hashmap usually depends on the hashing function. For example, say we have <=1000 objects and we create a map with 1000 entries. The perfect hashing function would map each entry to a unique entry in the map. In such a case we will have addition, deletion and search at worst case as O(1). Similarly, if we choose a worse hash function, which lets say maps each key to a single bucket (say a dumb hash function return 10, no matter what the input is), we will end up with a worst case search of O(n). Because of the above reason, we cannot guarantee a worst case performance for a hashmap, and hence a Binary Search Tree or a Red Black tree would sometimes be preferred in performance critical operations, as we can guarantee a max search time. Separate Chaining vs Open Addressing An obvious question is that which collision handling technique should be used. Both has its advantages. As a thumb rule, if space is a constraint and we do have an upper bound on number of elements, we can use open addressing. The advantage with Separate chaining is that it can grow indefinitely (if space is available).