Solving any problem requires one to analyze various available solutions and then look at factors like space complexity, time complexity, and ease of development.
Problem statement: Find the longest common prefix from N number of Strings.
Example: “kamal”, “kamalmeet”, “kamaljeet” should return “kamal”
Solution 1- Vertical Scanning
Approach: Start with the first element of each string and compare for equality. Continue till a point we do not find the same character.
Pseudo code:
-- for i=0 to n, of the length of the first (any) string ---- check if ith character is equal for all string ------ if not, return string from 0 to i-1 character
Code:
public String longestCommonPrefix(String[] strs) {
for (int index = 0; index < strs[0].length(); index++) {
char ch = strs[0].charAt(index);
for (String st : strs) {
// one of the strings has ended or char mismatch found
if (index >= st.length() || st.charAt(index) != ch) {
return strs[0].substring(0, index);
}
}
}
// if you reached here, first string is longest common prefix
return strs[0];
}Time Complexity: O(S) for Worst case all strings are equal, and S is the sum of all string lengths
Space Complexity: O(1) no additional data structure
Solution 2 – Horizontal Scanning
Approach: Start by comparing the first two strings and find the longest common prefix. Use this as input and compare it with next string and so on.
Pseudo code:
-- longestprefix = str[0] -- for strings in i=1 to N ---- longestprefix = findlongestprefix(longestprefix, str[i]) -- return longestprefix
Time Complexity: O(S)
Space complexity: O(1)
Solution 3- Divide and Conquer
Approach: Break down the array of strings into two equal parts, solve for the two subarrays, and find a solution for two results (repeat the process at each step).
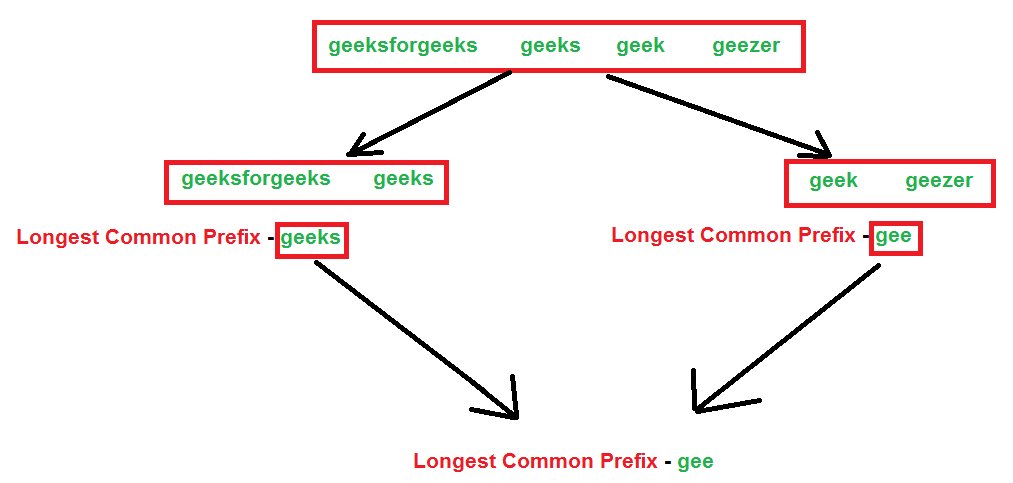
Additional Approaches