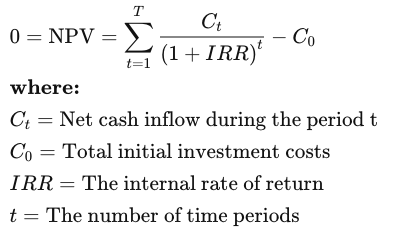The artical talks about how the importance of this skills increases multifold when it comes to a crisis situation. The improtance of Listening is in the fact that one cannot have all the information or perspectives. So it important to have discussions with team members and get different perspective.
Th article focuses on that fact that information available at the top level might be different from ground reality. This is another important reason to “listen” to diversified groups at different levels to not make biased decisions. “Then there’s the echo chamber. Whether we know it or not, most of us gravitate to people (and information) that confirm things we already think and believe. We’re drawn to individuals and ideas that concur with, and even end up shaping, our worldview. “
Someone living in silos is bound to be away from ground reality and might convince himself that “this is not going to happen to me”, and take incorrect decisions. It might be too late in the game when they realise their mistake and it is difficult to make ammendemnts at that time.
We tend to downplay or dismiss threats along the lines of “it’ll never happen to me, and even if it does, it won’t be that bad.” And when the chips finally do fall, we can become anchored to one particular plan or solution, even as the crisis shifts or changes direction. We may continue down one path long after it makes sense to do so, because of sunk costs: “we’ve come this far; it’s too late to change course.”
At times corporations need to make investment decisions. These decisions are important as they help firms build up their assets and future cash flows, at the same time would need considerable investments.
An important aspect of these investments is the time value of money, i.e. cash received earlier has more value than cash received at a later time.
Stages in Capital Budgeting
Stage 1: Investment screening and selection
Stage 2: Capital budget proposal
Stage 3: Budgeting approval and authorization
Stage 4: Project tracking
Stage 5: Post-completion audit
Financial Appraisal tools for Capital Budgeting
Payback Method: The payback period is the number of years it takes to recover the project cost. The payback method helps understand projects’ risk and liquidity and is easy to understand. On the downside, it does not consider the time value of money (TVM) and does not consider cash flows after the payback period.
An alternate to payback method is discounted payback, where instead of exact Cash Flow (CF), a discounted CF is considered to take care of TVM.
NPV: An important tool to evaluate projects is NPV or Net Present Value. In simple terms, NPV is is the difference between the present value of cash inflows and the present value of cash outflows over a period of time. If NPV>0, the project can be considered for acceptance.
– investopedia.com
Any project with NPV>0 is profitable. The higher the NPV, the more profitable is the project. So in the case of mutually exclusive projects (the only one that can be chosen), the one with higher NPV is preferred.
IRR or Internal Rate of Return: “The internal rate of return (IRR) is a metric used in financial analysis to estimate the profitability of potential investments. IRR is a discount rate that makes the net present value (NPV) of all cash flows equal to zero in a discounted cash flow analysis.” – investopedia.com. A Higher IRR rate makes the project more desirable.
To calculate IRR, set NPV=0 in the NPV formula mentioned above.
If IRR>WACC (Weighted Average Cost of Capital), the project is profitable.
Sunk Cost: Sunk cost is a cost that has already been incurred and as such, exists irrespective of whether the project is undertaken or not. For example the salary of the employees. This cost should not be considered as part of project cash flows.
Opportunity Cost: For example, if the company has land which is to be used to set up a factory for the current project. This cost will be added to the project.
Profitability Index: When comparing multiple projects of different sizes, directly comparing NPV might not make sense as one project might be worth 10000 and another might be 1000000. Profitability index or PI is calculated as NPV/ Initial investment and helps us calculate profit generated per dollar invested. A PI> 1 means the project is profitable.
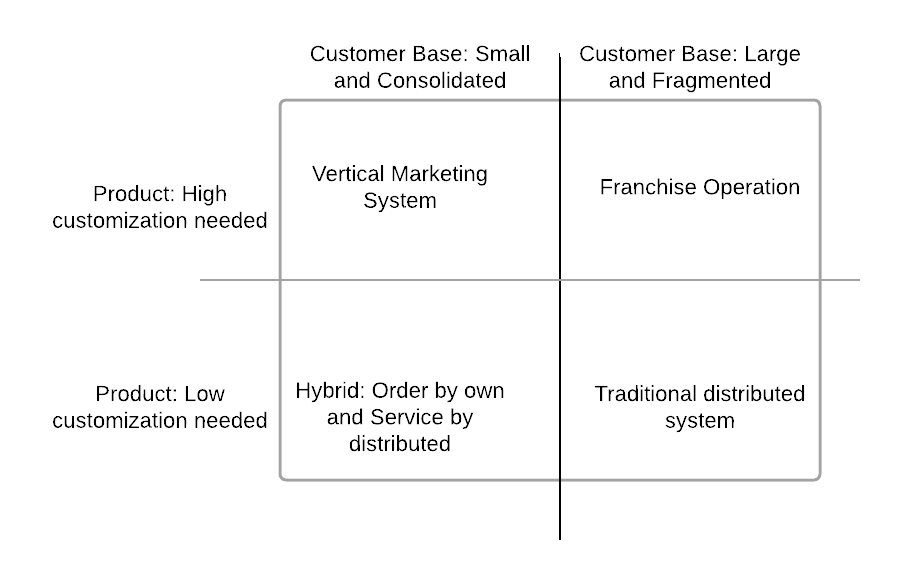
Search Goods: You search and compare characteristics before you buy, for example, in mobile- screen size, camera pixel, features, etc.
Experience Goods: where you can categorize as good or bad after experience only, for example, a stay in a hotel for the first time.
Credence Goods: Where you cannot categorize even after consumption for example an online course (you do not have anything to compare to unless you have taken another course on the subject).
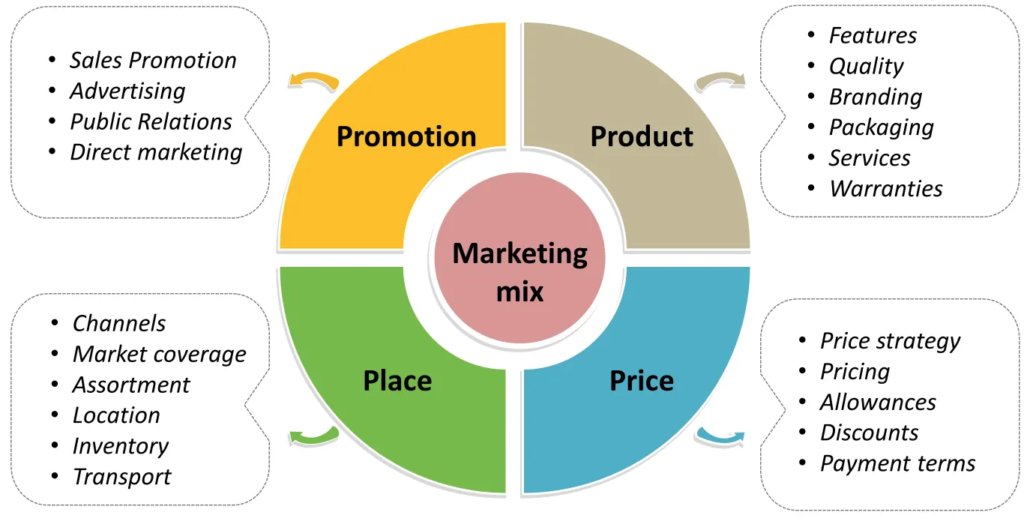
The second P of marketing is Promotion, which is a basic means for generating awareness about the product and create a desire to buy.
6M strategy model
Mission: What is the objective?
Market: Who are my customers?
Message: What I will tell my customers?
Media: How do I reach them?
Money: Budget
Measure: Was the campaign effective?
Two choices of channels
Personal Communication: Mostly more effective and low price via Telemarketing, Emailing or one on one meetings.
Impersonal communication: Mass media via Newspaper or T.V.
Place
The third P of marketing is Place. This gives the convenience of product availability at an arm’s length and helps build trust with customers.
Price
The fourth P of marketing is Price. A fundamental mistake done by companies is to think of price as cost + profit. Ideally one needs to do market research and competitive analysis to come up with the target price. Once one has a target price, it helps to come up with a target cost and help figure out how much to be spent on RnD, marketing, manufacturing, etc.
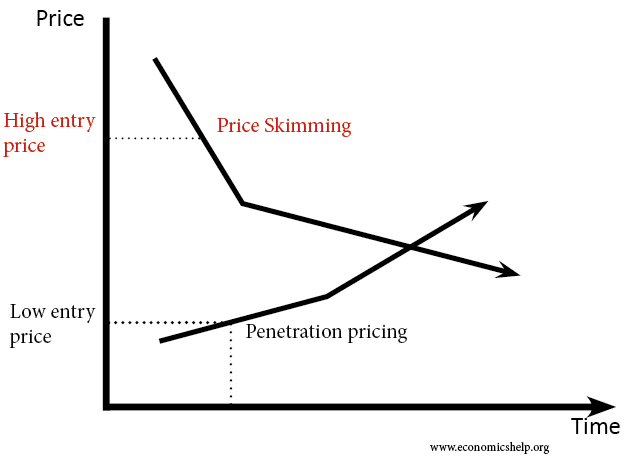
Two common pricing strategies are skimming (enter high and then move to low) and penetration (enter low and move to high).
In a dictionary Marketing is defined as “the action or business of promoting and selling products or services, including market research and advertising.“.
Before getting into depth, let’s take a step back and refer to the famous question asked in the paper “Marketing Myopia” by Levitt, i.e. “What business are you really in?“. The question forces one to think beyond what products are you selling to what “needs” of customers are you fulfilling. Marketing is all about understanding customer needs.
“Need” is a state of dissatisfaction. Need is a problem and “want” is the solution. I “need” to communicate, I “want” a phone. A “want” combined with a willingness to pay becomes the demand – I am ready to pay for an ‘iPhone”.
Another important aspect is to understand the “value” that the product is adding to the customer. Say, I have the option of buying two phones, I would like to buy the one which gives more value. Perceived value can be thought of as perceived benefits – perceived cost.
P(V) = P(B) – P(C)
While choosing a product over other
P(B1)-P(C1) > P(B2) – P(C2)
or B1-B2 > C1- C2
or Extra Benefits I am getting is more than the extra cost I am paying.
Segmentation – Targeting – Positioning
Segmentation is about grouping your customers by identifying commonalities based on their needs. Segmentation should not be geographical (urban/ rural, north/ south), or demographic (age, sex, education, economic class) but based on personality, values, lifestyle, and behavior.
Segmentation is a three-step process
Clustering
Profiling
Assigning a segment descriptor
Targeting is to select the segments that you will focus on.
There are the following targeting approaches
Mass Market: un-differential
Focus on all, but with the segmented approach: Diffeerential
Focused Strategy: One or two segments
Factors to be considered while targeting
Sales Potential: How much sales can be made for the segment?
Profitability
Consumer Maturity
Competition
Own Abilities
Competition: A less fragmented market can provide healthy competition. HHI or Herfindahl-Hirschman Index can provide a good measure to check how fragmented the market is.
HHI= s1^2 + s2^2 + s3^2 + …sn^2
where: sn=the market share percentage of firm n
0–Bad—-0.2——-0.4—————-Good——————-1
Positioning is “what to tell these customers?” so that they chose you.
While positioning one can take two approaches
Point of Parity or PoP: How are we similar to other products?
Category Point of Parity
Competitive Point of Parity
Point of Difference PoD: How are we different from other products?
SWOT Analysis
Strength – Weakness – Opportunity – Threat analysis is an old tool used by product teams to understand their characteristics. An important aspect one needs to take care of is all your strengths should map to opportunities, and similarly, weaknesses should map to threats.
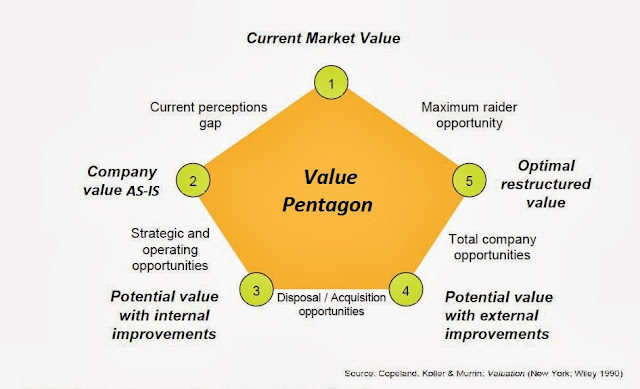
Company as-is value is the value of the company without any restructuring or change.
The company’s optimum value is the value that can be achieved after the restructuring is done.
Internal restructuring: Find out redenancies, wastages, remove bottlenecks.
External Restructuring: Merger, demerger, acquisition, etc.
Financial restructuring: Writing down useless assets, debt restructuring etc.
Shareholder vs Stakeholder value
When we talk about the value of the company, they normally have two approaches, increase shareholder value or stakeholder value. Both approaches have their pros and cons. The shareholder value approach is easy to track, as you can look at the numbers and figure out if the shareholder value has increased. But at the same time, this approach can be myopic and focus on short-term goals.
The stakeholder value approach has a broader view, where it talks about customers, employees, society, shareholders, and other stakeholders. The problem here it is hard to track as there is no direct way to track it. For example, giving better discounts and better salaries might help me keep my customers and employees happy, but might add to losses.
Measuring shareholder wealth creation
Market Value Addition or MVA is an important aspect to understand shareholder value. For example, there are two companies, A and B, both with a market cap of say 1000 crore. But the network of company A is 500 crore and company B is 250 crore. We can see MVA for company A is 500 crore whereas company B is 250 crores. In other words, the market view potential for growth in company B.
Corporate Restructuring
Corporate restructuring includes acquisitions, demergers, joint ventures, etc. For example, buying Corus helped Tata steel to jump from 55th ranked in steel revenue worldwide to 5th rank.
Corprate restructuring can be done by
Expansion: Absorption, Tender Offer, Asset acquisition, Joint venture, etc.
Contraction: Demerger – Spin off, split off, split up, Equity carve out etc.
Corporate Control: Going private, Equity buyback, leveraged buyout, etc.
Corporates can unlock value by demergers. Studies report that the observed value of the diversified firm is, on average, 15 percent less than the sum of the implied market value of its divisions, as compared to stand-alone market values of single-segment firms in those industries.
Factors behind diversification discount
Information hypothesis: the inability of markets to correctly evaluate conglomerate structures with unrelated businesses, leading to possible undervaluation.
Inefficient Management hypothesis: the inability of the managers to efficiently manage unrelated businesses.
Inefficient investment hypothesis: distortion of investment due to competition among units for resources.
Modes of asset disposition
Slump sale: Slump sale means the transfer of one or more undertakings as a result of the sale for a lump sum consideration. For example, Ruchi Soya buying biscuit business from Patanjali Natural Biscuits Pvt Ltd (PNBPL) for 60 crores.
Spin-Off: A spinoff is the creation of an independent company through the sale or distribution of new shares of an existing business or division of a parent company. When a new company B is carved out of company A, mostly shareholders of company A will get some proportional shares of company B.
Spin-Off helps in
Unlocking hidden value: establish a public market valuation for undervalued assets.
Undiversification: divest non-core business and sharpen strategic focus
Institutional sponsorship: Promote equity research coverage
Public currency: the public currency for acquisition and stock-based compensation programs
Motivating Management
Eliminating dis-synergies
Corporate Defence: Divest “crown jewel” asset to make the takeover of parent company less attractive.
Challenges in spin-off: There are certain aspects that need to be managed, for example, if the parent company has debt, how this debt will be divided between parent and spin-off company. The lenders need to agree on the arrangement.
Split-Off: In a split-off, the parent company offers its shareholders the opportunity to exchange their parent-co shares. For example, a big shareholder can give up shares in the parent company to gain controlling stakes in the new company.
Split-up: Division of a company into two or more publically traded companies. The difference here is that instead of the parent company and spun-off company, we have completely new companies into existence.
Equity Carve-out: Also known as IPO carve-out, the parent company sells a portion or all of its interests in a subsidiary to the public in an initial public offering.
Financial Restructuring
Cleaning up a balance sheet: writing off losses, writing down useless assets, can be done through asset restructuring and recapitalization.
Debt Restructuring
Strategy-Driven: Restructure debt by lowering the interest rates.
Crisis-Driven: When a company defaults, the company is forced to restructure debt.
Equity Restructuring
Special dividend: One-time dividend
Share buyback: reduces the shareholder base. As a regulatory requirement, the debt-equity ratio should be 2:1, after the buyback. Buyback can happen through the open markets, tender offers, and buyback from employees.
Stock Splits: helps with liquidity
Bonus Shares: When the company is growing fast but does not want to distribute cash in form of a dividend, a bonus share will help reward the shareholders.
Any system has the following core features – Inputs, Processes & Procedures, Output, and Feedback. When we think of HRM systems, we can look at these features as
Inputs- People with their Knowledge, Skills, Abilities, and personalities.
HRM Processes, Procedures, and Policies
Outcomes- Organizational Perspective and Employee Perspective
Feedback – Internal or External
Core objectives of any HRM system from Org side
Productivity or Performance (Ability * Motivation* Opportunity)
Job Satisfaction
Motivation or Engagement
Low Attrition
Objectives from Employee side
Employee Contract: When an employee joins a company, there is a formal contract between employee and company. It is HR’s responsibility to make sure terms are fulfilled (leaves, medical benefits, etc)
Psychological Contract: A more important aspect from the employee’s side is a psychological contract which is unwritten, for example, the firm will help employees to learn and grow.
HR system has following processes
Recruitment and Selection
Orientation
Performance Management -> Compensation (Increments & Incentives), Training and development
Exit Processes
HR Environment impacting policies
External
Economic
Product Market
Labor Market
Government regulations
Social environment
Internal
Organization Culture
Business strategy
Org Size
Leadership
Technology
Lifecycle stage
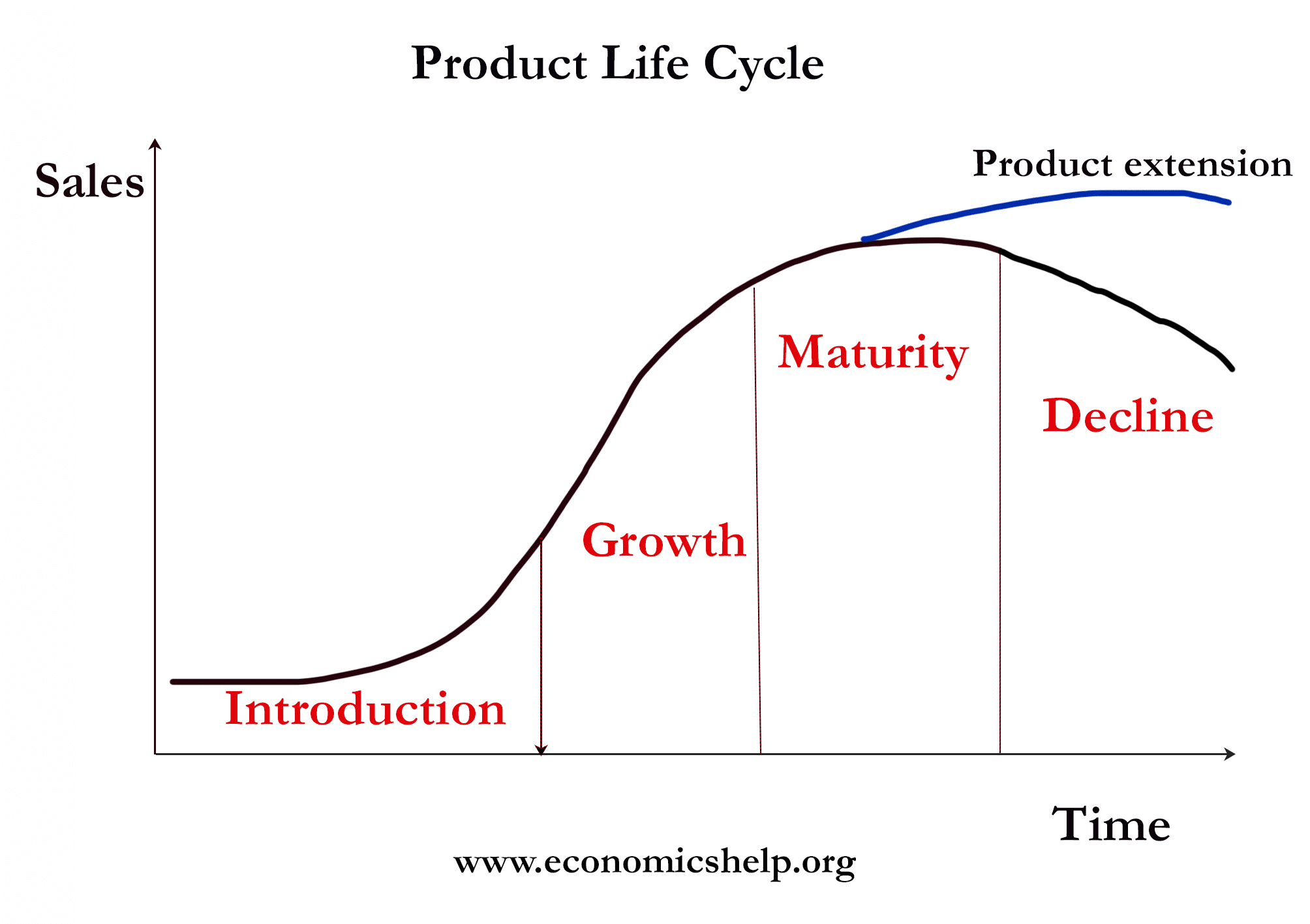
Any organization goes through various lifecycle stages like startup -> Growing -> Mature -> Decline. HR policy will be impacted by the current stage of the organization. For example, an org in the startup phase will have different policies to attract organizations like profit-sharing in terms of ESOPs.
HR Strategies
Innovative Strategy: Firms need employees to be innovative, risk-taking, develop new skills, and exchange ideas. Firms allow employees to become stockholders by providing stock options as part of pay.
Quality Enhancement Strategy: Firms that are looking to gain a competitive advantage by improving the quality of products and production. Mostly comes with a fixed job description but employees need to be flexible and adaptable to new technologies. Performance appraisals are mostly short-term and result-oriented.
Cost reduction strategy: Firms with relatively fixed and explicit job descriptions try to gain a competitive advantage by cost reduction strategy. Narrowly designed career paths encourage specializations, expertise, and efficiency. Appraisals are short-term and result-oriented.
Different organizations are looking for different aspects in an employee. For example, a startup would look for employees
Risk-taking
Ready to experiment
Tolerance for failure- fail fast and learn
Entrepreneurial
Problem solver
Handle ambiguity
Innovation = AMO (Ability * Motivation * Opportunity)
When we talk about nonmarket strategy, there are many factors that impact a firm. Here we will talk about the three most important aspects that a firm needs to be thinking about are – land, labor, and climate. We already talked about the climate in the last post. We will discuss more labor and land here.
Volkswagen Emission Scandal: An important case to understand the impact of non-market forces on a company is the case of Volkswagen which came into light in 2014-15. The company used a defeat device to cheat the emission tests giving false readings while the cars were being tested for emission against CCA emission standards. Volkswagen had ambitious revenue and sales goals, but at the same time, it suffered from high labor and manufacturing cost due to the way decision-making power had a big role in labor representations. Once the scandal was highlighted, Volkswagon came up with a strong nonmarket strategy under the new CEO where they invested heavily in future-oriented electric cars.
Land: Land is an important input for any business, to open factories, offices, storage units, etc. any firm needs land. Along with being important, the land is also a very complicated input to attain. Most land is owned by private owners or households. Obtaining a big chunk of land in a developing country like India which has a high population density can be a big challenge. The difficulty factor will vary based on factors like population density, type of land (land currently used for agriculture or residential purpose), connectivity (factories want easy access to roads, airports, shipping ports, etc.), and so on.
An interesting case study for land acquisition in India is the Tata motors Singur case in West Bengal, where the organization failed to set up the factory due to opposition from landowners. Without getting into political aspects, we will look at the Land acquisition act LARR which was the result of the Singur case.
Rather than a forceful acquisition of land, consent-based ownership transferred needs to be in place. One solution is to go for an auction-based option given to landowners, where every owner can give their expected value of the land. The firms can choose the lowest bidders and an option of giving an alternate land can be given to people who are not ready to give up land for money. Another option that is in need of the hour is to rather than going horizontally, firms need to think more of going vertically when setting up new factories to help optimized usage of land. Also, profit-sharing options should be given to landowners.
Labor Laws: Labor is a necessary requirement for any kind of business. Any firm looking to set up a business at any location needs cost-effective skilled labor. A very simple calculation is how much investment of X per hour in labor is yielding in terms of outcome. Labor laws in any country will give directions for the discharge or dismissal of workers, wages, bonuses, lay-offs, retrenchment, and work conditions. For example, minimum wages laws help ensure that firms are paying a basic minimum wage so that workers can live a decent lifestyle.
Climate change is an important factor in recent times which has been talked about in business and non-business environments. Every degree rise in temperature is going to have a long-lasting impact on our planet. Every business is a social entity, hence has a responsibility of making sure it is looking at growth keeping future generations in mind.
Sustainable development meets the needs of the present without compromising the ability of future generations to meet their own needs.
To contain global warming to a 1.5 degrees C rise, global net human-caused emission of carbon dioxide CO2 would need to fall by 45 percent from 2010 levels by 2030, reaching net zero around 2050.
Firms need to change the way they conduct business over next 2-3 years.
Business Megatrends and Sustainability
Business Megatrend refers to societal and economic shifts such as globalization, the rise of the information society, and so on.
Current Megatrends: Rapid Urbanization, climate change, and resource scarcity, shift in global economic power, demographic and social changes, technical breakthroughs, etc.
Sustainability is an important megatrend. GM’s decline can be clearly traced to its failure to understand how quality considerations would transform the auto industry. Similarly, Kodak’s dominant position in photography eroded quickly as it missed the signals in digital technologies.
For sustainable growth, a firm needs to do well in all four quadrants. Firms need to reduce material consumption, reduce pollution, reduce waste generation. This can be achieved by a greater level of transparency and responsiveness
Some of the strategies including adopting green technologies and work towards inclusive wealth creation and distribution (reduce poverty), will help firms move towards sustainable growth.
There can be cases where we have all the needed data is available, and we need to make decisions such that a given objective is achieved in the best possible manner while satisfying conditions imposed.
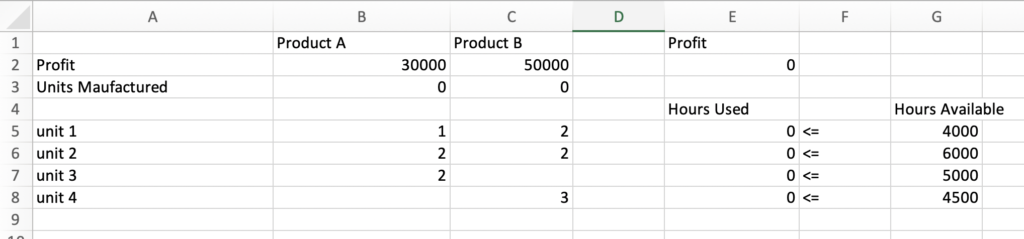
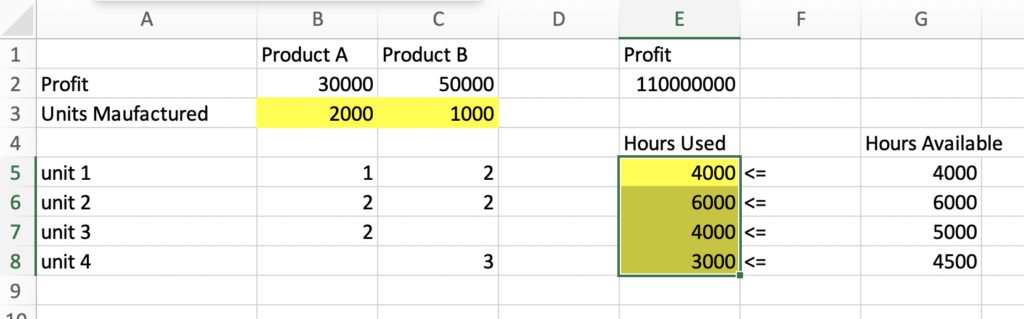
To understand the concept let’s take the problem of optimizing resource utilization and maximizing profit, where we have all the details on how much resources are being used by the products. Say in a factory, we are building 2 products, Product A and B. The Factory has 4 units. Product A generates 30000 in profit and manufacturing needs 1 hr in unit 1, 2 hr in unit 2, and 2 hr in unit 3. For product-B, it generates 50000 in profit and its manufacturing needs 2 hr in unit 1, 2 hr in unit 2, and 3 hrs in unit 4. As given constraints, we know that unit 1 can operate 4000 hrs, unit 2 can operate 6000 hrs, unit 3 can operate 5000 hrs and unit 4 can operate 4500 hrs in a month.
To solve this problem, we are going to use the Simplex Linear Programming method. This is available off the shelf in Microsoft Excel, so we will set up the data in an excel sheet.
Simplex LP
Let’s try to understand the data here before moving ahead. We have added data for Product A and B, Profit data for per unit, units manufactures is just a placeholder for now, and then we have given the number of hours spent in each unit by both the products.
Column E2 has total profit, i.e. number of units for product A * per unit profit product A + number of units for product B * per unit profit product B or =SUMPRODUCT(B2:C2, B3:C3)
Column E5 to E8 is also dynamically calculated. For example, E5 has Time spent by product A in unit 1 * units manufactured Product A + Time spent by product B in unit 1 * units manufactured Product B or B5 * B3+ C5 *C3. Similarly, E6,7 and 8 are calculated.
Once we have an excel setup, the next steps are easy. Go to Data -> Solver -> Object (choose column E2 where we calculate total profit) -> For “To”, let the default max be selected as we want to maximize profit -> For Changing variable cells choose B3 and C3 where we have units manufactured for A and B -> Add constraints by selecting Hours available cell reference i.e. from E5 to E8 is <= G5 to G8 (constraints can be added one by one or in one go when the comparison is same i.e. in this case <=) -> Choose Solving method as Simplex LP.
When you click on solve, you will get an optimal solution
The solution says that we should produce 2000 units of product A and 1000 units of product B with a maximized profit of 110000000.
Now there can be situations like due to some operational issue we lost 100 hrs in unit 1 or there is a way we can borrow 100 hours for unit 2 from another factory, what is the impact on our profit. Or say due to change in market dynamics product A can give a profit of 40K instead of 30 K. An valuable tool to look at all the related data is sensitivity analysis. When we clicked solve button on Solver, we are given an option to generate a sensitivity analysis report.
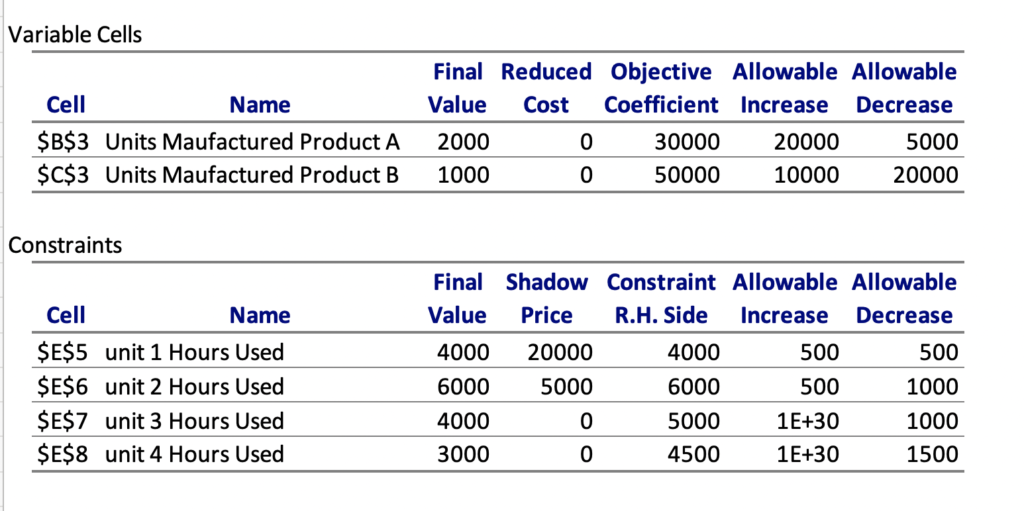
The generated report looks like
sensitivity analysis
The upper 2 rows here talk about 2 products. So coming back to our question, that if instead of 30K, we get a profit of 40K from product A, shall that change my product mix. The report says that there is no impact on product mix for increase by 20 K or decreases by 5K, or in other words, product A profit can range from 25K to 50K and current product mix remains valid. Similarly for Product B, the profit range is 30K to 60K. Any change beyond this will need us to recalculate the analysis.
Coming to Constraint data, shadow price indicates that each hour in the current unit has this much impact. For example, if we can increase unit one capacity by one hour, from 4000 to 4001, we can increase our profit by 20K, so getting extra 100 hours will result in 2000K, and reduction by 100 hours will have the same negative impact on profit. The range of increase and decrease of 500 each says that the calculation is valid till this range, so if we say unit one can get more than 500 hours, we will need to recalculate the values as the current calculation will no more hold good.
In the last post. when I talked about Sampling and Estimation, we discussed P-Value in regression analysis and how this should be less than our error threshold α (alpha). We will understand what is this α value and how we get this while understanding the hypothesis testing.
Hypothesis testing is all about coming up with a hypothesis and figure out if should reject or not. The two components we have here are
Null Hypothesis or H0
Alternate Hypothesis or H1
Conditiions
Together the two hypotheses should cover all possible outcomes
The two hypotheses should be mutually exclusive.
α is the tolerance level or level of accepting the error. so we can say
P-Value or Probability of current outcome <= α [Reject H0] P-Value or Probability of current outcome > α [Do not Reject H0]
Reject H0
Do not Reject H0
H0 is True
Type 1 Error
OK
H0 is False
OK
Type 2 Error
Hypothesis testing
α is Probability of Type 1 Error.
Let’s take an example, the judiciary system says “innocent till proven guilty”. So consider this as the null hypothesis
H0 Person is innocent (we need to reject this to prove the person is guilty) H1 Person is guilty
Type 1 Error: Person is innocent but is treated guilty (we target to minimize this) Type 2 Error: Person is guilty but is treated innocent