Load Balancing is an important technique in cloud-native application design to achieve scalability, reliability, and availability. The load can be distributed among nodes (physical or containers), based on rules like round robin, weighted, performance-based, geographical distribution, etc.
Load Balancing can be achieved at the following levels
DNS Level: DNS level load balancing is a method of distributing incoming network traffic across multiple servers or IP addresses by using DNS (Domain Name System) servers to resolve domain names to IP addresses. You can choose distribution riles based on need, for example, you might want to send traffic originating from Europe to hit Europe servers whereas traffic from North America to hit North America servers. While resolving the DNS, the traffic manager will choose the backend endpoint based on the rules set.
Layer 7 or Application Layer: In Layer 7 load balancing, the load balancer analyzes the content of the incoming requests, including the HTTP headers, URLs, and other application-specific data, to determine how to distribute the traffic. For example, we can set rules that /images pattern is getting redirected to a backend, whereas /videos pattern is to another. Additionally one can have features like SSL termination, and WAF (Web Application Firewall, that will protect from threats like SQL injection attacks, Cross Site Scripting or XSS attacks, etc.) implemented.
Layer 4 or Transport Layer: Layer 4 load balancers can route traffic based on basic criteria such as source IP address, destination IP address, source port, destination port, and protocol type. At the transport layer, the load balancer does not have access to request data, hence decisions can only be taken at IP or Port level. At the same time as no parsing is involved, the overall performance is better.
In one of the recent team discussions, I heard the terms Rule Engine and Recommendation Engine being used interchangeably. This was confusing, but understandable as some overlapping areas are there when we try to solve a problem where we are trying to take a decision based on given inputs. In truer terms, these are actually complementing technologies that can help reach a final decision in a complex situation.
What is a rule Engine?
Mostly based on a specific business scenario, where a set of rules can predict the outcome.
Use cases:
An insurer determines whether a candidate meets eligibility requirements.
A retailer decides which customers get free shipping and a discount.
Implementation: As a lot is written and talked about when it comes to the implementation of a rule Engine, rather than reinventing here, let me use an example
@Rule(name = "Hello World rule", description = "Always say hello world")
public class HelloWorldRule {
@Condition
public boolean when() {
return true;
}
@Action
public void then() throws Exception {
System.out.println("hello world");
}
}
What is a recommendation Engine?
A very common feature you see in almost every website these days, let it be an e-commerce website recommending you products based on your past purchase history or an OTT site recommending videos to watch next. This takes into account users’ historical data plus data from other users with similar histories and tries to predict future likings. For example, users who like movies A, B, and C ended up looking a movie D.
Apache Kafka is an open-source, distributed, publish-subscribe messaging system designed to handle large amounts of data.
Important terms
Topic: Messages or data are published to and read from topics.
Partition: Topics can be split into multiple partitions, allowing for parallel processing of data streams. Each partition is an ordered, immutable sequence of records. Partitions provide a way to horizontally scale data processing within a Kafka cluster.
Broker: Kafka cluster supporting pub-sub
Producer: Publish data to the topic.
Consumer: Subscribe to the topic.
Offset: Unique identifiers for messages. Each record in a partition is assigned a unique, sequential offset, and the order of the records within a partition is maintained. This means that data is guaranteed to be processed in the order it was written to the partition.
ZooKeeper: Apache ZooKeeper is a distributed coordination service for managing distributed systems. If a node fails, another node takes over its responsibilities, ensuring high availability. ZooKeeper uses a consensus algorithm to ensure that all nodes in the system have a consistent view of the data. It helps Kafka to manage coordination between brokers and to maintain configuration information.
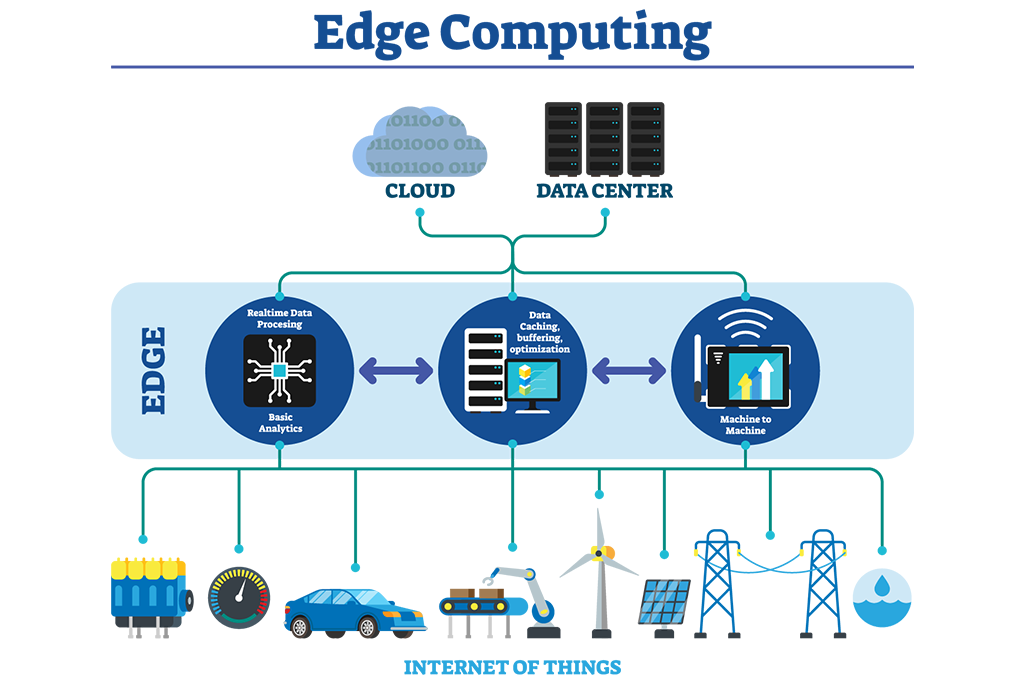
Edge Computing takes distributed computing close to the information source, rather than relying on centralized data centers. This approach is relatively popular for systems that involve IOT devices.
The idea is to keep computation near to source, to reduce latency. Decisions can be made faster as data does not need to be sent to long distance. This also reduce the amount of data sent to central servers as some level of data filtering and analysis is pre-processed at edge locations.
Edge Computing architecture usually contains following components
Edge devices: Devices that collect data from sensors, cameras, and other sources. Examples include IoT devices, cameras, and industrial equipment.
Edge gateway: An edge gateway acts as a bridge between the edge devices and the back-end systems.
Edge server: This is a server located at the edge of the network that is responsible for processing and analyzing data. It can run applications and services that are optimized for low-latency and high-performance requirements.
Fog nodes: These are intermediate devices that sit between the edge devices and the cloud or data center. They are responsible for processing and analyzing data, similar to edge servers, but they are typically more powerful and capable of running more complex applications and services.
Cloud/Data center: The data that is processed at the edge is then sent to a cloud or data center for further analysis, storage and sharing.
Management and orchestration platform: This is a platform that manages and monitors the edge devices, gateways and servers, and allows for the deployment, configuration, and management of edge applications and services.
In the series of exploring designs for popular systems, I will try to come up with Twitter’s system design today.
Functional Requirements
User should be able to Tweet
User should be able to follow and view tweets of others on their timeline
User should be able to search for tweets
User should be able to view current trends
Non Functional requirements
Availability
Performance
Eventual Consistency
Scale 150 million users with 500 million tweets per day or ~5500 Tweets/Second
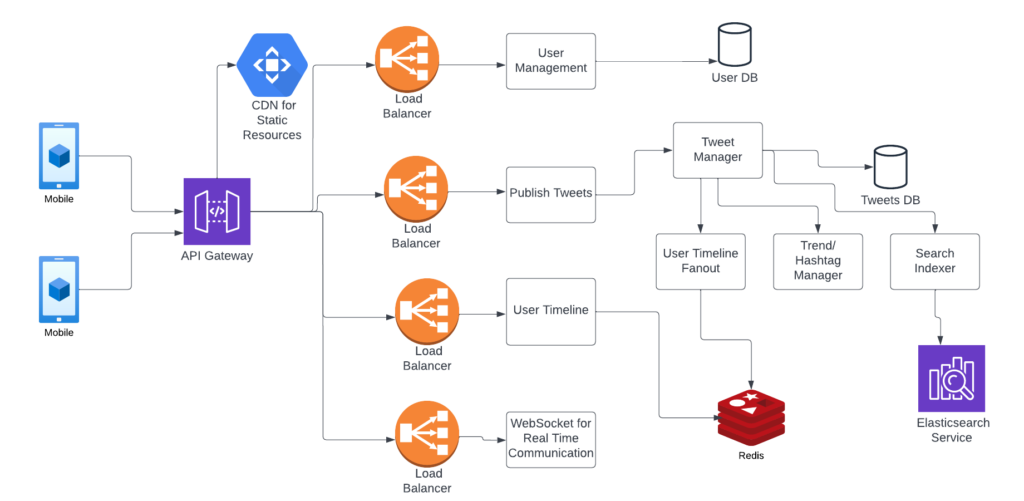
30000 view of Architecture
30000 view of Twitter Architecture
There are one or two aspects of the above design which are very interesting. The first one we can see is the user timeline. This can be a complicated piece, whenever a user login into the app, he should see his timeline, which will show all the tweets from people he is following. The user might be following hundreds of accounts, it will not be feasible to calculate tweets from all these accounts at runtime and create timeline data. So a passive approach makes sense here, where we can keep the user timeline data in a cache beforehand.
Say user A is following user B, and user B publishes a new tweet, at that time itself, user A timeline will be updated with a new timeline getting added to user A timeline data. Similarly, if 100 users are following user B, all the timelines get updated (Fanout the tweet and update all timelines).
It can get tricky if user B has millions of followers. A different approach can be used in this case. Assuming there are not many such popular users, we can create a separate bucket for handling these popular users. Say user A is following user C (celebrity), so instead of updating the timeline for C beforehand, tweets for all such celebrity users can be pulled in real-time.
Another important aspect is hashtagging and trends exploration. For all the tweets coming in, the text can be tokenized and tokens can be analyzed for most usage. For example, when a cricket match is going on in India, many people might tweet with the term match or cricket. Again these trends might be geo-location-based as this particular trend is a country-specific one.
In this series of trying to understand designs for popular systems, I am taking up Whatsapp in this post. Please remember all the designs I am sharing in this series are my personal view for educational purposes and might not be the same as actual implementation.
To get started let us take a look at the requirements
Functional Requirements
User should be able to create and manage an account (Covered already)
User should be able to send a message to contact
User should be able to send a message to a group
User should be able to send a media message (image/ video)
Message Received and Message Read receipts to sender
Voice Calling (Not covering here)
Non Functional Requirements
Encryption
Scaleability
Availability
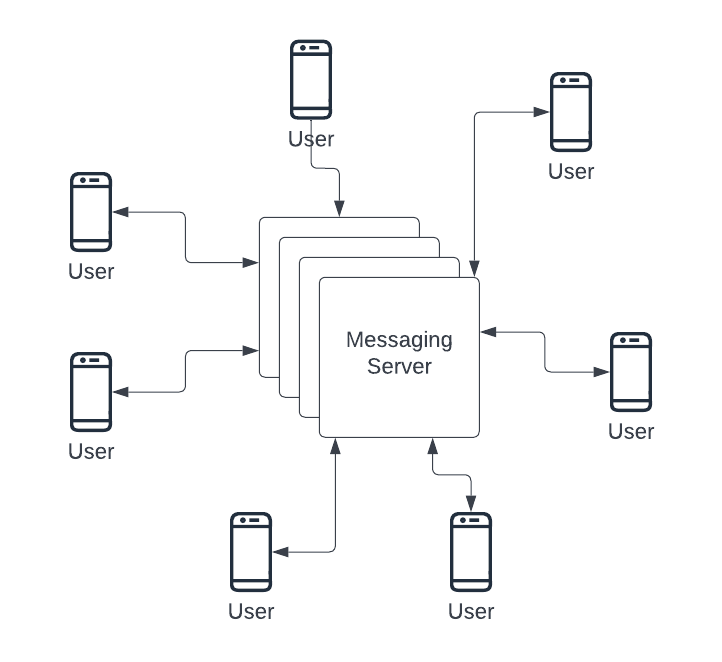
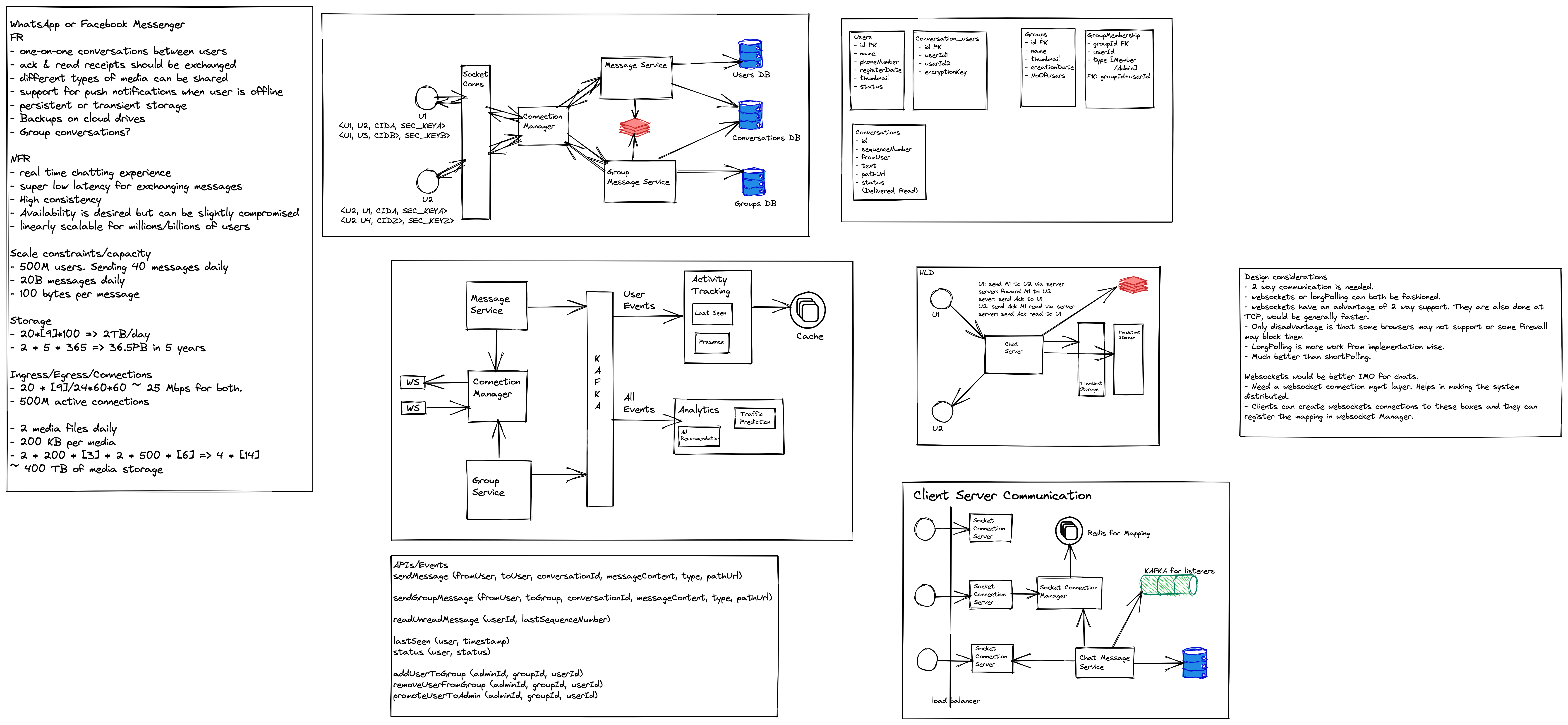
At a very high level, the design looks very straightforward
The first important thing that we see here is that communication is not one-way like a normal web application where the client sends a request and receives a response. Here the mobile app (client) should be able to receive live messages from the messaging server as well. This kind of communication is called Duplex-Connection where both parties can send messages. To achieve this, one can use long polling or web sockets (preferred).
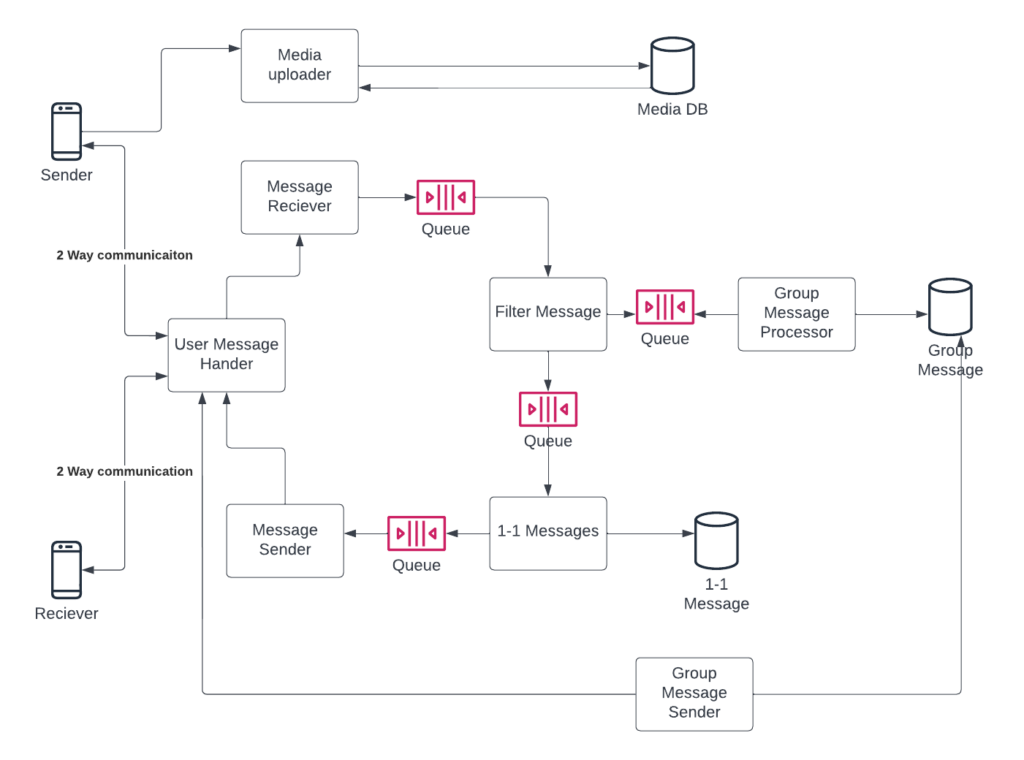
Communication Management: When a user sends a message, it will be sent to the queue of messages received, from where it will be processed and sent to the queue for messages to be sent to users.
Media Management: Before sending the message for processing, media is uploaded and stored in a storage bucket, and the link is shared with users, which can be used to fetch the actual media file.
Single/ Double/ Blue Tick: When a message is received and processed by the server, the information is sent back to the user and marked single ticked. Similarly, when the message is sent successfully the receiver is marked double tick and finally, when the receiver opens the message, it is blue ticked for the sender.
The problem we are trying to solve is to create a service that can take a large URL and return a shorter version, for example, say take https://kamalmeet.com/cloud-computing/cloud-native-application-design-12-factor-application/ as input and give me https://myurl.com/xc12B2d, a URL easy to share.
The application looks simple, but it does provide a few interesting aspects.
Database: The Main database will be used to store long URLs, short URLs, created dates, created by, last used, etc. as we can see this will be a read-heavy database and should be able to handle large datasets, a NoSQL document-based database should be good for scalability.
Data Scale:
Long URL – 2 KB (2048 chars)
Short URL – 7 bytes (7 chars)
Created at – 7 bytes (7 chars for epoch time)
last used – 7 bytes
created by – 16 bytes (userid)
Total: ~2KB
2KB * 30 million URLs per month = ~60 GB per month or 7.2 TB in 10 years
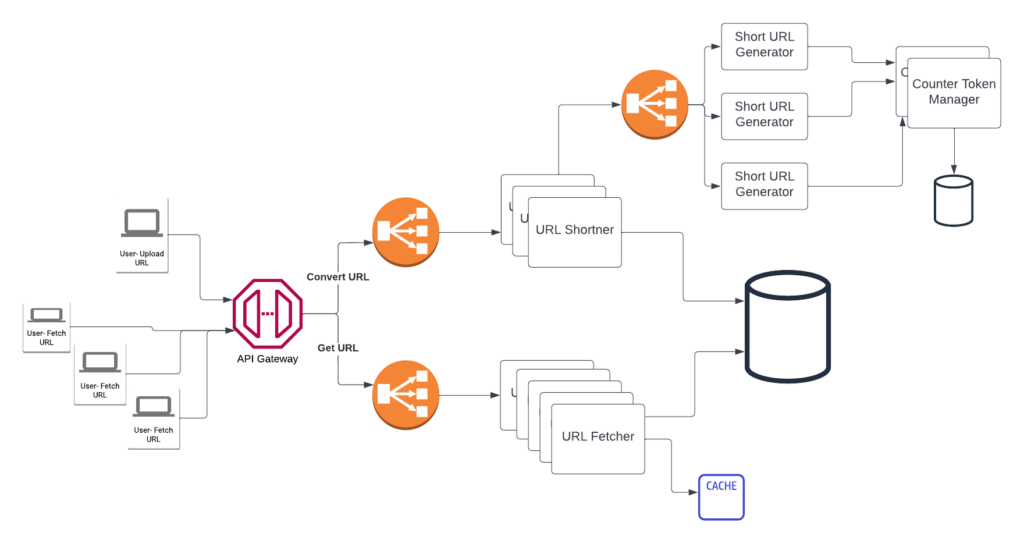
Format: The next challenge is to decide the format of the tiny URL. The decision is an easy one, Base 10 URL would give you 10^7 or 10 million combinations for a 7-character string whereas a Base 62 format will give 62^7 or 3.5 trillion combinations for 7 character string.
Short URL Generator: Another challenge to solve is how to choose a random 7 Base 62 string for each URL.
Soln 1: Use MD5 which returns a string of 20+ chars, we can take the first 7 characters. The problem here is taking the first 7 characters might lead to a collision where multiple strings have MD5 with the same first 7 characters
Soln 2: Use a counter-based approach. A counter service will generate the counter which gets converted to Base 62, making sure all requests get a unique Base 62 string. To scale it better, we will have a distributed counter generator.
User is able to upload or download files via a client application or web application
User is able to sync and share files
User is able to view the history of updates
Non Functional Requirements
Performance: Low latency while uploading the files
Availability
Concurrency: Multiple users are able to update the same file
Scaling Assumptions
Average size file – say 200 MB
Total user base- 500 million
Daily active users- 100 million
Daily file creations- 10 per user
Total files per user- 100
Average Ingress per day: 10 * 100 million * 200 MB = 200 petabytes per day
Services Needed
User management Service
File Handler Service
Notification Service
Synchronization Service
File Sync
When Syncing the files we will break the file into smaller chunks, so that only the chunk which has undergone updates will be sent to the server. This architecture is helpful in contrast to sending the file to the server for every update. Say a 40 MB file gets broken into 2 MB chunks each.
This architecture helps solve problems like
Concurrency: If two users are updating different chunks, there is no conflict
Latency: Faster and parallel upload
Bandwidth: Only chunk updated is sent
History Storage: New version only need a chunk of data rather than full file space
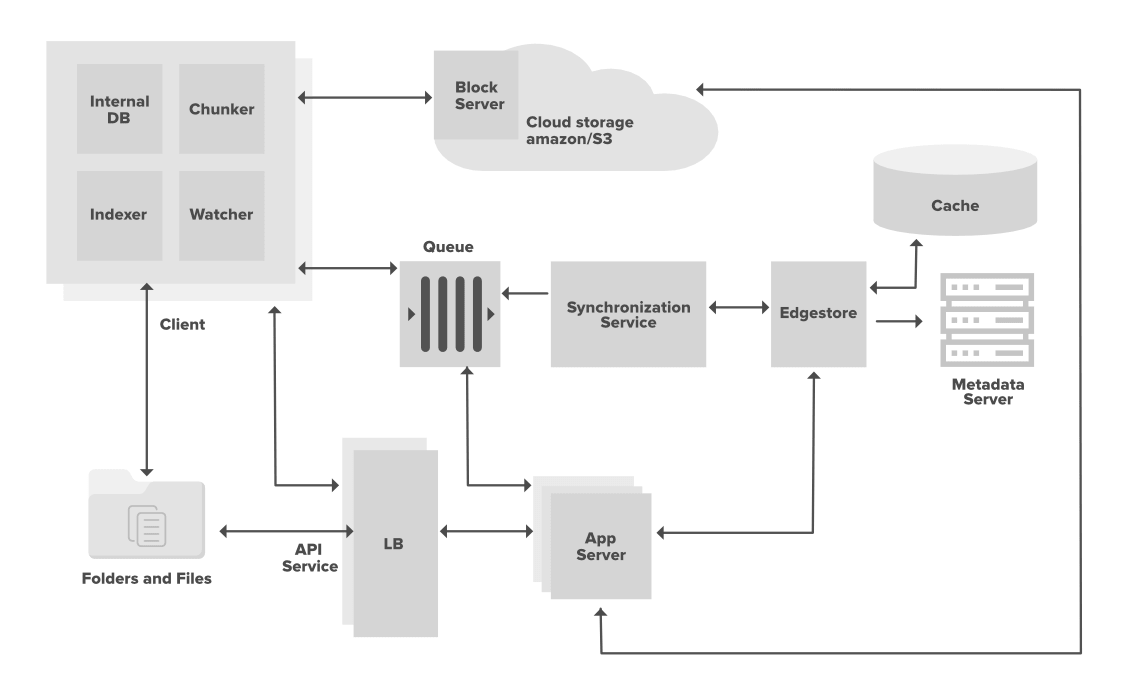
The most important part of this design is the client component.
Watcher: This component keeps an eye on a local folder for any changes. It informs Chunker and Indexer about changes.
Chunker: As discussed above, the chunker is responsible for breaking a file into manageable chunks
Indexer: On receiving an update from watcher, Indexer updates the internal database with metadata details. It also communicates with Synchrnozation service sending or receiving information on updates happening to files and syncing the latest version.
Internal DB: To maintain file metadata locally on the client.
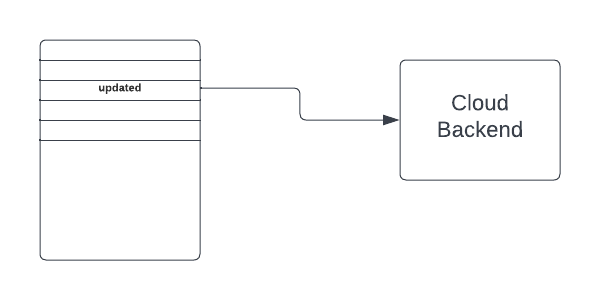
Cloud Storage finally stores the files and updates. Metadata server maintains metadata and helps inform clients about any updates through synchronization service. Synchronization service adds data to the queue which is then picked by various clients based on availability (if a client is offline, it can read messages later and sync up the data). Edge store helps provide details to clients from the nearest location.
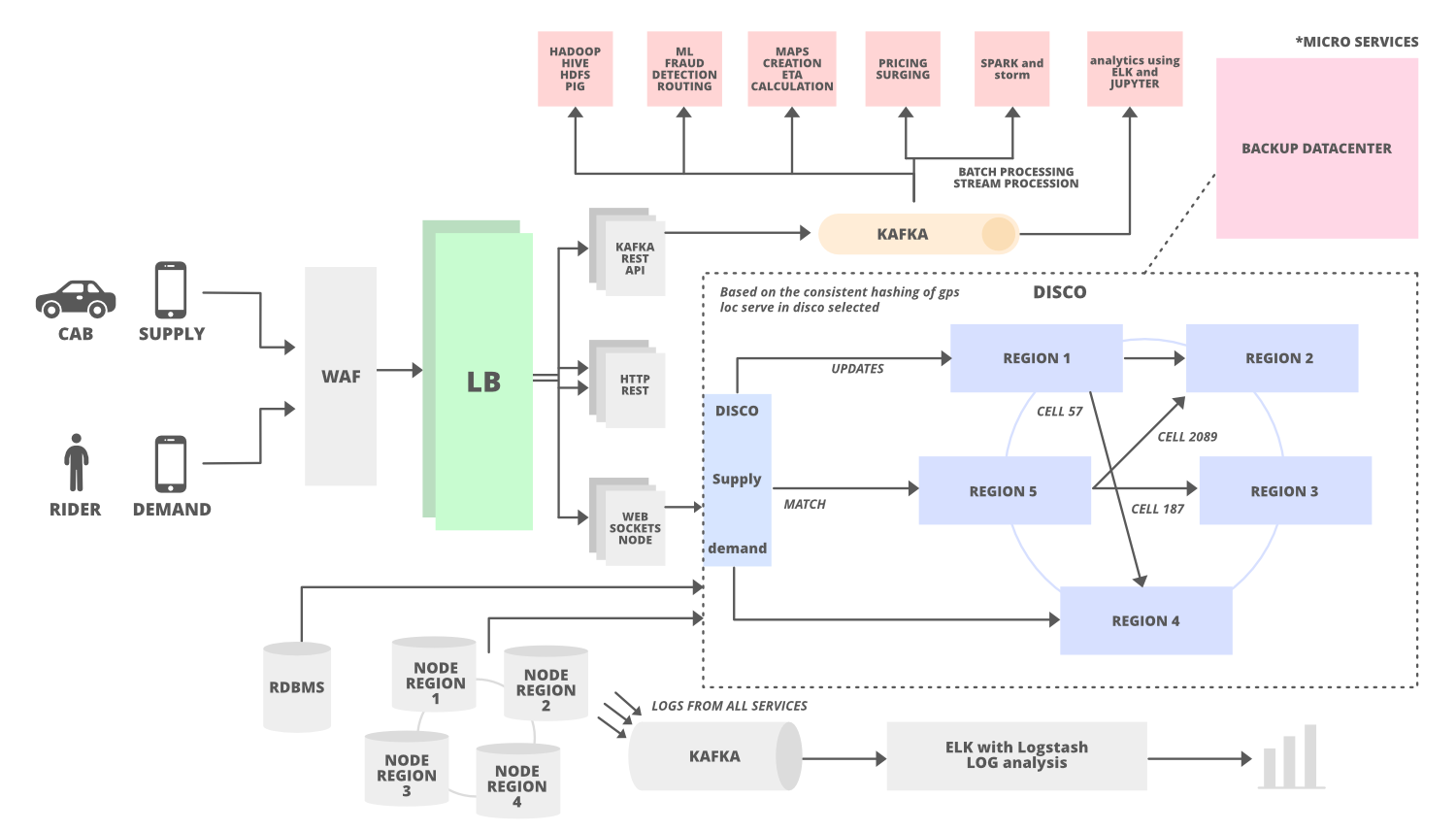
In this series of popular system designs, I will take up design for a taxi aggregator service like Uber. Please note that the designs I share are based on my understanding of these systems and might not be the same as actual designs.
Before Getting on with Designs, let’s list down the requirements
Functional Requirements
User (Rider) should be able to create an account
Driver should be able to register
Rider should be able to view cabs availability in near proximity along with approx ETA
Rider should be able to request for a cab
Driver should be able to receive a trip request.
Driver can accept the request (Assumption: Multiple drivers will receive the request and one will accept)
Trip starts when rider boards the request.
When trip ends, Rider can make the payment and receive a receipt.
Rider can rate the Trip / Driver
Rider can view Trip history
Driver can view Trip history
Non Functional Requirements
Availability
Scalability
Performance
Consistency
Localization
Services to be created
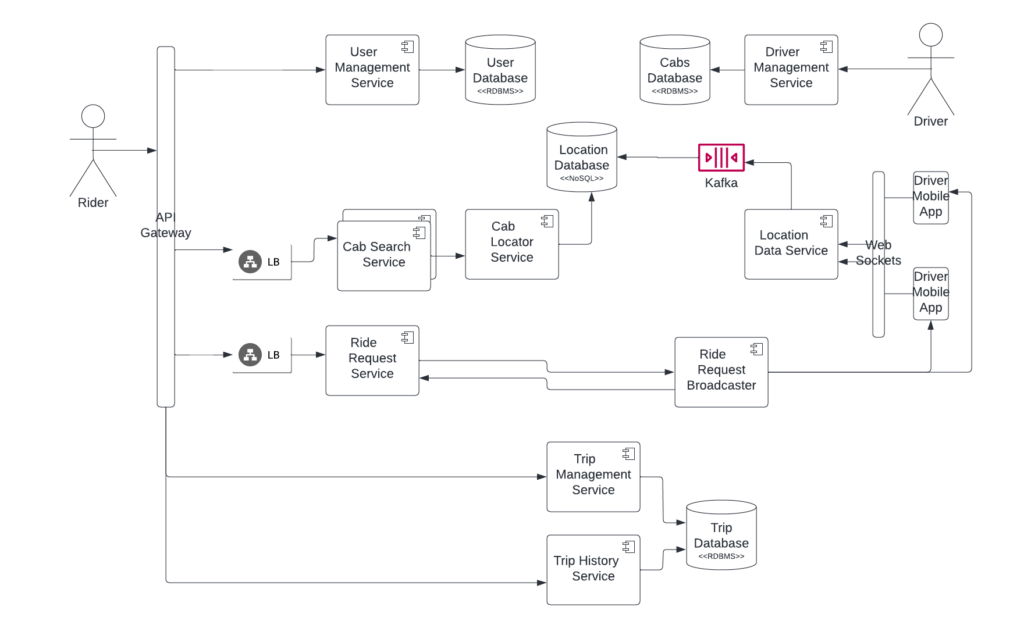
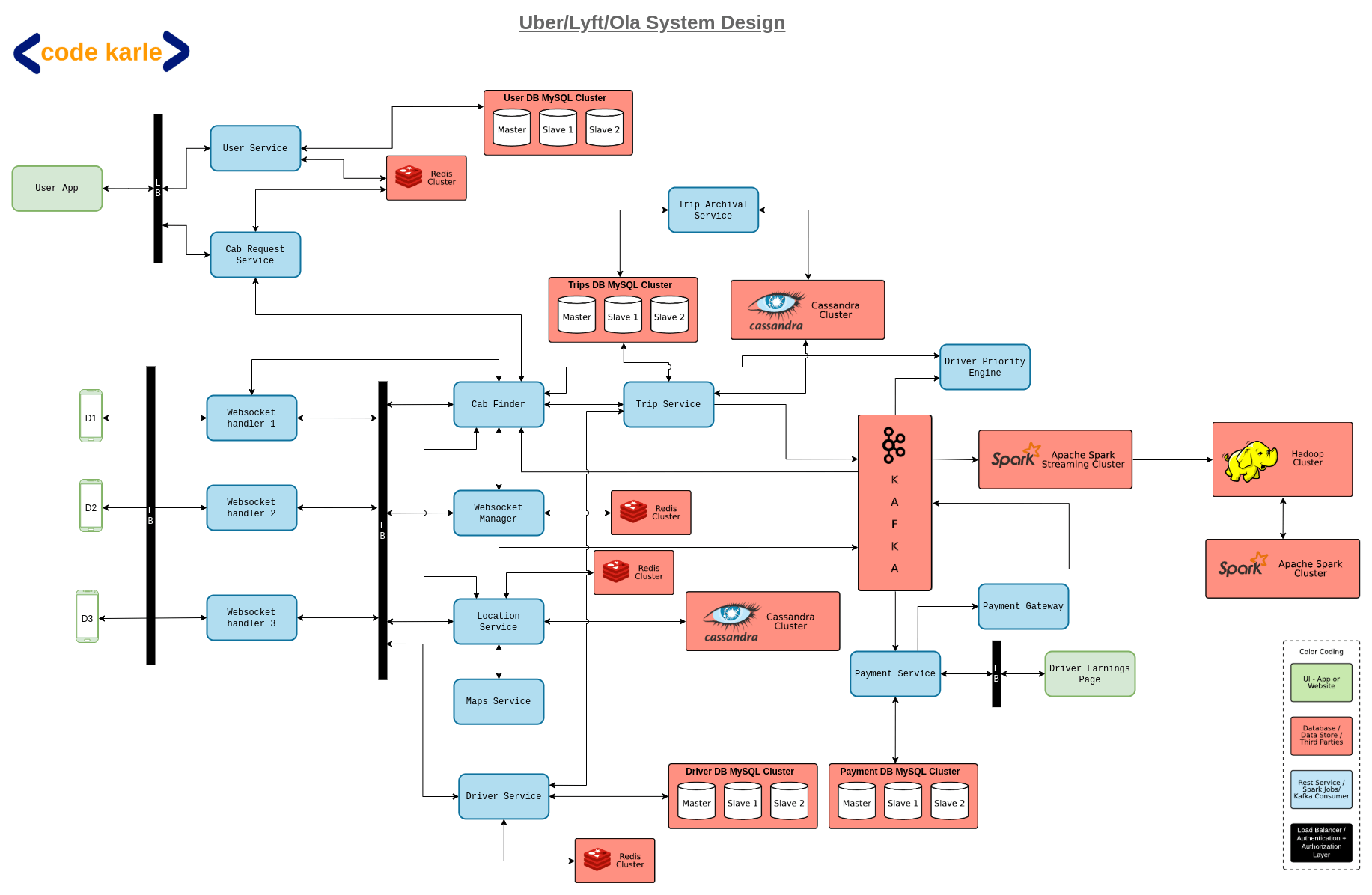
User Management Service
Driver Management Service
Cab Search Service (Takes Riders location and finds nearby cars)
Ride Request Service (Rider’s request is shared with drivers for acceptance)
Trip Management Service
Trip History Service
Database Requirements
User Data
Driver and Cab Data
Cab Location Data
Trip Data (Current and Historical)
A high-level design might look like
An important question one needs to answer is about the Cab locator service works. The class way of GeoHashing should be used, where the whole area will be thought of as square boxes. Say a user is at Lat, Long position, we will try to find all the boxes around the current location within a given radius. And then find all the Drivers available in these Geo boxes.
Designing or architecting a system is a complex task. One needs to think of various aspects that can impact a system. At a high level, we bucket the requirements into two parts – Functional and Non-Functional. Functional requirements, in simple words, can be thought of as functionalities one needs to build. Non-functional requirements can be complex as they usually will not be called out explicitly and as an architect, you need to figure out after discussions with various stakeholders.
In this post, I would try to look at the system design for Netflix. Of course, it is a complex system and it is difficult to cover in one post, but I will try to touch upon important aspects.
Functional Requirements:
Account Management: Create Account/ Login/ Manage and Delete the Account
Subscription Management
Search
Watch a Video: View/ Download for offline viewing
Recommendations: User-based/ Generic/ Top trends/ Genre
Device Synchronization
Language Selection: Audio/ Video
Non-Functional Requirements:
Performance: Realtime streaming performance
Reliability
Availability
Scalability
Durability
Data needed:
number of users
daily active users
the average number of videos watched per day/ per user
Microservices-based architecture: Netflix is an early adapter of microservices and helped popularize the use of microservices. Microservices help Netflix manage its critical services by keeping them stateless, secured, scalable, available, and reliable.
CDN or Content Delivery Network: In the image above we see Open Connect, which is Netflix’s CDN. For any application which has consumers across multiple geographies, CDN is an important piece. This helps deliver content like images, videos, JavaScript, and other files from a location nearest to the user helping improve performance. In addition, Netflix provides Open Connect Appliances to ISPS free of cost, which helps ISPs save bandwidth and helps Netflix Cache content for better performance.
Transcoding: Any video getting uploaded to Netflix then gets converted to videos of various resolutions. The video gets uploaded to a queue from where it is taken up by transcoder workers who after converting the video upload them to AWS S3. When a user clicks on a video to be played, the best option is chosen based on the client and bandwidth.
API Gateway: ZUUL is the API gateway used by Netflix, which provides features for gateway like security, authentication, routing, decorating requests, Beta testing (based on routing), etc.
Resiliency: It is a resiliency library by Netflix. It handles scenarios like timeout handling, failing fast by rejecting requests when the thread pool is full, circuit breaker when the error rate is heavy, fallback to default response, etc.
Cache: Netflix uses EV cache to provide performance, reduced latency, better throughput, and reduced overall cost. EV cache is a custom implementation of Memcache, which is not dependent on RAM and can use SSD.
Database: Netflix uses MySQL for data that needs ACID properties, data like user data. Read replicas are used to improve query performances. Cassandra is used for NoSQL, to keep data like browsing and watching history. Older history data can be moved to the compressed cheaper data store.
Logs Management: All log data is sent to Chukwa through Kafka. You can view logs on the dashboard. Finally, logs can be sent to S3 for further retention and usage.
Search: Elastic Search is used for indexing and searching.
Recommendations: Spark is used for data analysis. it helps rank content based on user history as well as using data from users with similar tastes. For example, if two users have given similar ratings to a movie, their tastes might be similar. Also if a user watches comedy content mostly, the recommendation engine might suggest more comedy content.