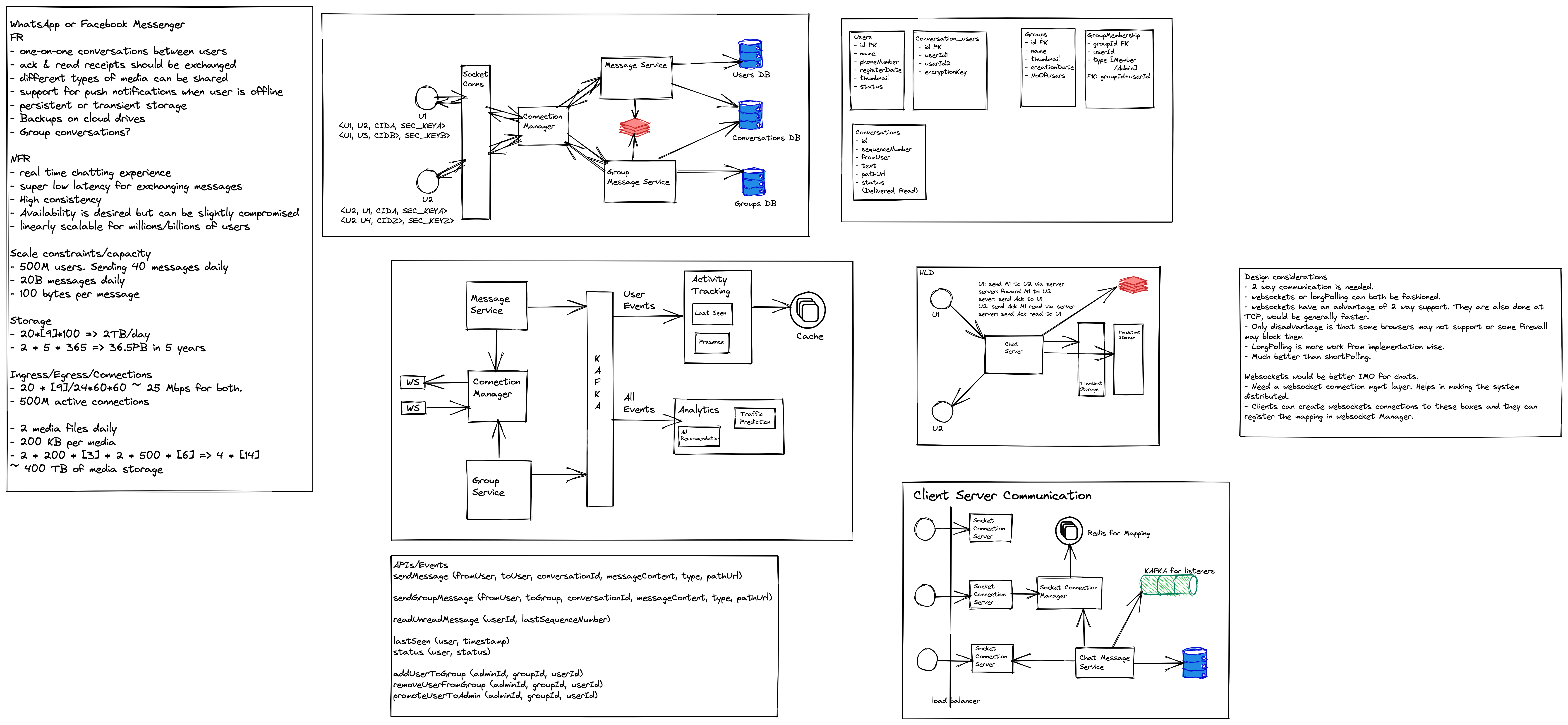
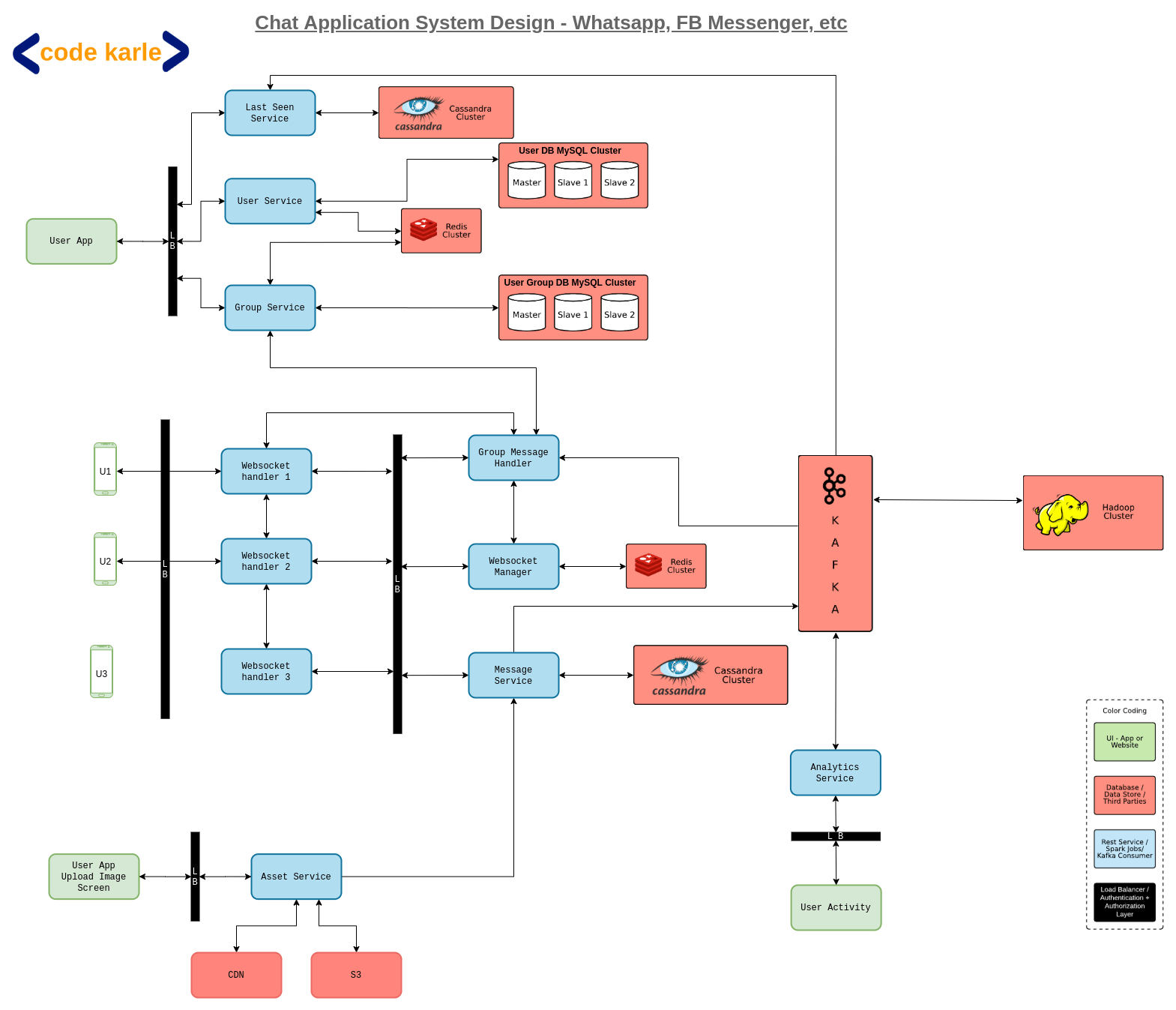
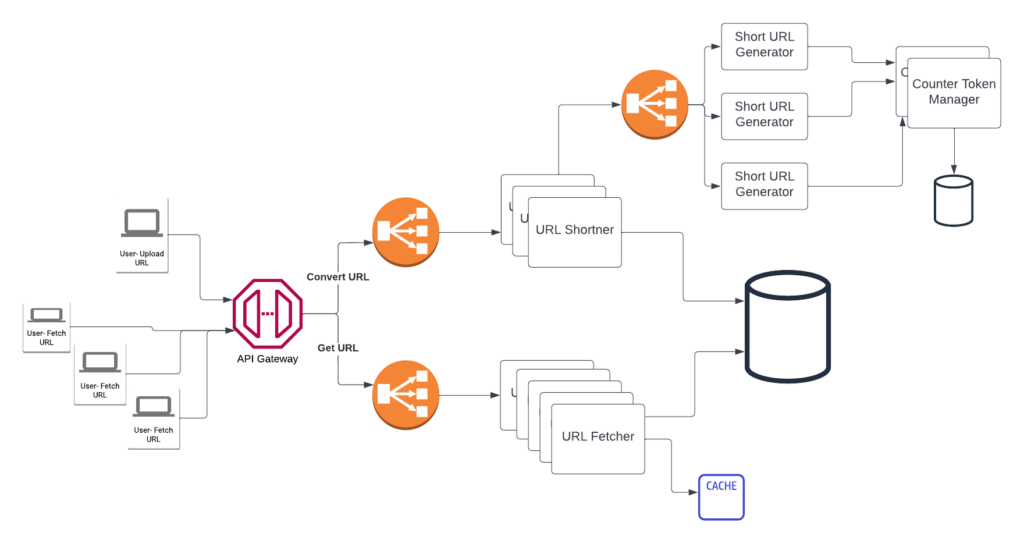
Cloud-native application design consists of three core pillar decisions- Compute, Database, and Storage. Most cloud providers give various options for all.
When starting with application design, the first decision the team needs to make is how and where we will deploy it.
Virtual Machine: Age old classic option is to go for a virtual machine, where the development team takes complete control over setting up servers, managing virtual machines, Magaing the health of machines, Scalability, etc. Examples are AWS EC2, Azure Virtual Machine, and Google Virtual Machine.
- Pros– Easiest to get started, gives more control over setup.
- Cons– The dev team is responsible for managing the machine, the least cost-effective solution.
Containers: Lightweight containers give the perfect solution for a microservices-based design. Container Manager like Kubernetes gives off-the-shelf solutions for managing the health and scalability of container-based implementation. Most Service Providers give options for off-the-shelf service like Azure Kubernetes Service or Amazon Elastic Kubernetes Service.
- Pros: Best suited for Microservice-based solutions, lightweight hence cost-effective, and easy to manage.
- Cons: Learning curve to making sure correct use of tools like docker and Kubernetes
Functions: Next deployment option is to deploy using Functions as a Service. Again a very good fit for Microservices gives you on-demand execution of code options. Service Provider gives us options like Azure Functions or AWS Lambda to build our code as Functions.
- Pros: Can be cost-effective with pay based on the execution model as you only pay for execution time.
- Cons: Does not fit all use cases, not all scenarios are supported (most vendors have a limit on the time it will take for execution), and Vendor locking.
Specialized options: Apart from the options mentioned above, most service providers give you specialized options like Azure gives you App Service and AWS has Elastic Bean Stalk that helps you deploy popular technologies like Java, Python, etc directly.
- Pros: Being Managed services, helps the dev team get free from managing underlying infra and focus on development. Also provides features like monitoring and scaling off the shelf.
- Cons: Learning curve to understand the framework and vendor locking as the deployable is specific to the vendor.