A quick and easy way to calculate function points- just enter relevant values here
http://www.engin.umd.umich.edu/CIS/course.des/cis525/js/f00/artan/functionpoints.htm

A quick and easy way to calculate function points- just enter relevant values here
http://www.engin.umd.umich.edu/CIS/course.des/cis525/js/f00/artan/functionpoints.htm
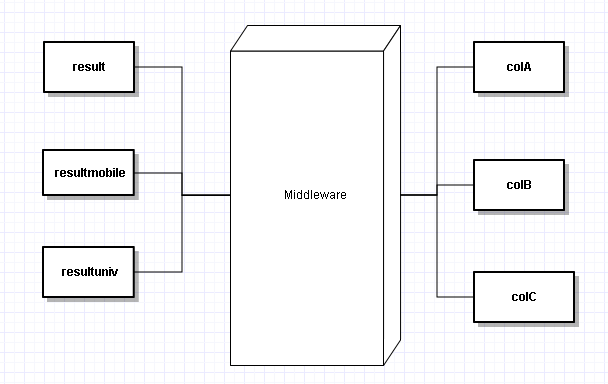
If you look around for the term Middleware, you will see it being used widely but unfortunately not explained properly anywhere. What is middleware? If you are working on simple web applications, the possibility is that you have mostly worked on client-server paradigm without worrying about middleware concepts. Middleware genrally comes into picture when we are dealing with multiple(atleast 2) applications. It helps these applications talk to each other, even if these applications are on different platforms, technologies and servers.
How does Middleware do it? Lets take a simple example. We have a college A, which has an inhouse application (colA app), used to track students data, attendence, results etc. Now there is an internet application which is supposed to display results of students online (result.com). Now result.com app needs to communicate to colA app to fetch student result data. We introduce a middleware application which helps these 2 app communicate. Let’s say this is message oriented middleware, so as soon as a new result is available on colA app, it writes it on a queue of middleware app. Now middleware might do some processing on the data if required and add it to another queue, which is listened to by result app.
Why can’t result app directly talk to colA app? It can, but what will happen if complexity increases and we introduce many new applications into the arena. Say we have hundereds of colleges and tens of result apps. And to complicate it further, college apps also need to communicate to each other. Just imagine the comexity that each app is listening to tens of other apps and fetching data from tens of apps. Each app need to worry about security, concurrency, connectivity, handling so much load. Different apps might be using different technologies to make the communication difficult. With introduction of middleware, we are moving all the complexity out of the apps so that they can focus on their core areas and let middleware worry about handling load, setting up clustors, managing security, dealing with different technologies and platforms.
There are times when I get confused if a web application is sufficient to solve a problem or I should be creating a web service. So I tried to get into depth of the two approaches.
What is a web application? web + application. A software application is something that is helping a user to achieve some specific goal, like MS Word, Calculator, Email Client etc. A web application, similarly, is an application which is available over a network or internet, it might be online banking application, some e-commerce application etc.
What is a web service? A service is similar to application in a sense that it is achieving a goal, but instead of being independent application, a service is providing inputs to some other application. For example, a service to add up two numbers, will take 2 numbers from a calculator app, add up two numbers, and return back to the calling applications.
Now how to take up the question if I should be creating a web application for a particular problem or web service. Let’s go back to calculator app, which needs a functionality to add 2 numbers. Web application approach will be to implement the add function inside the app, which is good enough if I know that this function is to be used only with this app. Web service approach will need the sum service to be independent of any application. This gives advantage that the same service can be used by multiple applications, this includes web apps, mobile apps or desktop apps as they will just need to connect to network and call the service to fulfill a requirement.
Above, we have defined web app and web service from a functional aspect. Technically, web service is a specialized web application only. A rule of thumb states that if your requirements want a user interface, you will need a web application implementation, but if your requirement does not need a interface but will return only some data, a web service is a good fit.
These days there is a lot of buzz around the word ‘scalability’ in IT world. The concept is actually not new, I have been designing scalable systems for last 9 years, but the idea has definitely changed since then.
How meaning of scalability has changed in last few years?
If 5-6 years back, I was creating a system to support say 10K users, and someone would have told me to make it scalable, I would have thought of making the system it in such a way that it can support double or may be 4 times or max 10 times the users in next 3-4 years. But with the applications like facebook, amazon, ebay, twitter the idea about scalable system is different. Now the user base can increase exponentially in matter weeks. And that is what every organization wants.
What is the impact of change?
Impact of the change is that now you do not want a system which will need a good amount of change if your user base is increasing. Earlier, as number of users used to grow slowly, it will give you time to think, design, redesign, upgrade the system, but now, as user base can increase with much more speed, you want a system which can scale up within minutes and it should be able to it automatically.
How to achieve scalability in today’s world?
As the demand has changed, so has technology. Cloud computing has made it much easier for us to create scalable systems. Key component choices to be made while creating a scalable solution
1. Design: Design of application/ code should be able to handle infinite load.
2. Database: If you are expecting your data load to grow beyond a few million, you might want to go for NOSQL over RDBMS.
3. Hardware: you should be able to add in new hardware and replicate the application on new servers within minutes. Cloud system can help you here.
4. Load balancing: If our application is getting distributed/replicated over multiple servers, we will need to take care of load balancing so that no server will choke.
I heard this term ‘Dependency Injection’ (DI) a couple of months back, and since then it was at back of my mind and I was planning to read about it. It sounded like some mysterious concept, but it turned out to be a simple one.
DI (or Inversion of Control) is nothing but transferring responsibility of initialization of instance variable to the calling class. This helps in loose coupling and testing of classes.
A very good post on the topic:
http://jamesshore.com/Blog/Dependency-Injection-Demystified.html
Additional Info:
http://stackoverflow.com/questions/130794/what-is-dependency-injection
What is deadlock?
From wikipedia- A deadlock is a situation where in two or more competing actions are each waiting for the other to finish, and thus neither ever does. It is often seen in a paradox like the “chicken or the egg“. The concept of a Catch-22 is similar.
So what is a deadlock in terms of operating system job scheduling. It is same, there are multiple jobs which are trying to gain control of resources and end up in a situation where each process is waiting for some resiurce which is being held by another process.
How to avoid such situations? Banker’s algoirthm is the answer. As the name suggest, the algorithm uses intellegence shown by a banker in order to maintain safe amount of cash in the bank, so that bank never runs into a situation where it has no money to fulfill its customer needs.
A very simple example will be, say the bank has 60K amount. There are 3 customers A, B and C. A needs 30K for its project, B needs 25K, and C needs 40K. Now we know that bank can fulfill need of all three customers, but not at once. So ideally the bank will fulfill one customer’s need at a time, wait for the customer to return the money (we will ignore interest for simplicity, and we will assume money will be returned by cistomer as soon as project is finished though in real workd cstomer might need some time), and then move on to next. Which is not effective use of money as customers will need to wait while others finish. In practical world, not all the money will be needed for projects in one go, so the bank can ask customers how much amount they will need at what stage, and at what time they can return the money, and try to organize the finances in a way that all customers can finish there projects in best possible time. The same kind of logic is used by job-scheduler of on operating system to make sure all jobs gets finished in best possible time, avoiding deadlock.
Lets say customers provide this data to bank
Customer A: Need 10K at start
Customer B: Need 10K at start
Customer C: Need 10K at start
The bank sees it can afford to give this money to all the customers as it will still have enough money to fulfill needs of all the customers.
In stage 2, all customers again come up with a demand of 10K. Now the bank sees if it will allocate all the money, it will run out of money with none of the projects being successfully completed, hence no point of recovery. So it must deny some of the customer. Safest bet will be to refuse the amount to C and tell it to wait till bank has enoght fund. Allocate the money to A and B, as it will still have enough money to give to these customer to finish the project.
So C is put on hold and A and B moves on with the project. Now say A comes up with demand of 10K, which bank will fulfill and A will be able to finish project successfully and return 30K. Now bank can provide money to C, as it knows it will have sufficient funds for other customers.
The same intellegence is used by an OS to make sure the system never runs out of resources.
Had a requirement today to restrict emails from our postfix server to only to some specific domains/ email addresses. It turned out to be pretty simple
At the end of /etc/postfix/main.cf just add
smtpd_recipient_restrictions = check_recipient_access hash:/etc/postfix/access permit_auth_destination reject
and at the end of /etc/postfix/access add the domain names/ email addresses which can accept emails
kamalmeet.com OK abcd@gmail.com OK
Now update postfix db
postmap hash:/etc/postfix/access
and finally restart service
service postfix restart
That’s it
Recently faced an issue of having duplicate rows in a table of production database. Normally to delete or insert data into table, primary key is used, but due to bad database design somehow duplicate rows got added. Exact same data, each column was same.
A little bit googling solved the issue.
delete from temp_table where rowid not in (select min(rowid) from temp_table group by column1, column2);
Note that this might not straight away work for a table with huge data. A simple way to solve that issue is to create a temporary table, say temp_table2, copy data for duplicate rows from temp_table to temp_table2. Now clean up temp_table2 using above delete command and delete all the duplicate rows form temp_table. Insert back all the remaining, cleaned up, rows from temp_table2 to temp_table.
Whenever we write a piece of code or algorithm to solve a problem, we need to understand how much time will the algorithm take to solve the given problem. This is important information as we have to make a decision based on amount of input data, that if the given solution will be sufficient or needs further improvement. The time complexity is mostly expressed in big O notation, called as- order of.
In simple words, complexity of the code can be known by checking amount of times a particular piece of code gets executed and how that is dependent on input data.
1. Lowest level of time complexity (hence best), which can be achieved is constant time complexity or is Order of 1, O(1). This means the time taken by algorithm will always be constant irrespective of input data.
e.g. Find sum of N consecutive numbers.
No matter what the value of N is, we just need to find (N*(N+1)/2).
OR print a string str 100 times.
for (i=0 to 100){print str;};
In above cases the code will take a constant time independent of the input.
2. Second best complexity that can be achieved by a code is of order of log n or O(log n). If you are familiar with logarithms, you already know what I am talking about. If you are not comfortable with logs, read on. When we say log n, we are by default assuming base as 2 (if not specified otherwise).
So if I say
log (base 2) n=x, this can also be thought of: n=2^x.
For further simplicity, all we are trying to say here is, that with every iteration of the code, the previous step problem dataset gets reduced to half (½).
A classic example for this would be binary search. We have a sorted array and we are trying to find put a number.
Array arr={1,3,6,8,11,13,17, 22, 28}
search if x=3 is available or not
Algo-
1. take 2 variables start and end at start(1) and end(28) of array.
2. Find mid of the array (position 5, No 11).
3. Check if it is the desired number x
4. if No at mid position is >x, set end to mid, else set start to mid.
5. Repeat 2 to 4
Notice that every time we execute step 4, we are reducing our data set from previous step to half.
3. Complexity of order N, O(N)that is directly proportional to number of input data set. Note when we say O(N), actual complexity can be 1*N, 2*N, 100*N, k*N where k is any constants which does not change with N.
A very simple example here would be searching a number in a random array
Array arr={4, 3, 88, 15, 67, 13, 56}
find x= 15
we just need to loop through whole array once (in worst case), from 0 to N and check if the number is available at the position.
4. O(n log n).If you look carefully, we have just added above 2 complexities for log n and n. So we are talking about a code which has complexity of log n and gets executed n number of times.
A very simple example is of tree sorting, where we create a binary search tree for a given array. We know insertion in binary search tree taken log n time. Now instead of adding just one element, we are trying to add n elements (whole array), so we are talking about n* log n complexity.
5. O (n^2). If you have n elements as input, and you have to loop twice all these elements, we are using n*n steps. Example would be bubble or selection sorting
Array arr={4, 3, 88, 15, 67, 13, 56}
Task- sort the array
for ( i=0 to N-1)
for(j=i+1 to N-1)
{
if(arr[i] is greater than arr[j])
swap(arr[i],arr[j]);
}
A couple of days back I had to provide estimate for a requirement from Clients. I thought of checking some estimation techniques on internet to cross verify. I searched for term ‘estimation techniques’ and started browsing. The first link was some article (very informative) and then I clicked on second link and to my surprise, I found a powerpoint which I created 3-4 years ago to give a session to my team. I uploaded the ppt on slideshare and since then it had more than 19000 hits. I am so happy that people are still using what I created long time back 🙂