I have a strong belief that Solutions Architecture is as much of a science as it is an art. There is no set of fixed rules you can apply to get a final architecture. There are rules, but they can get changed based on kind of project, teams and constraints you are working with.
Coming to 4+1 Architectural view of software architecture, Krutchen shared an interesting way of looking at software architecture in this paper.
Original paper- https://www.cs.ubc.ca/~gregor/teaching/papers/4+1view-architecture.pdf
In crux, the paper suggest that we can look at any software architecture from 4 perspectives or views to get a complete picture.
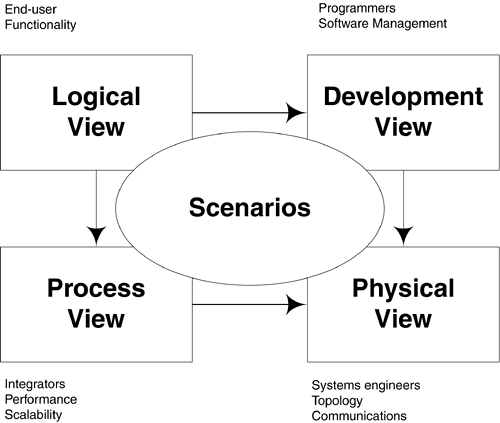
Logical view: This is end user view of the system. How many entities or classes are there and how they interact, for example, how Employee will be related to Department and Project, what will happen when someone joins or leaves an organization.
UML: Class Diagrams, State Diagrams.
Process View: This talks about how the business works as a process. If you need to open an account in a bank, what process needs to be followed. In addition, we take care of non-functional requirements like scalability, performance etc in this view.
UML: Activity Diagrams
Development View: This is a view for developers, understanding how the system will be implemented (also known as implementation view). How many components will be created and how will they interact with each other.
UML: Component Diagram, Package Diagram
Physical View: This view explains how this system will be deployed physically. What kind of machines are there and how these are interacting.
UML: Deployment diagram
Scenarios: Scenarios or Use cases are given special attention. Because before getting into any other views, one needs to understand all the use cases we need to handle for the system being developed.
Well the paper explains about these views in details, so here I would like to add my understanding of how to use this model in agile development methodology.
Agile Perspective: When you are building a software in agile manner, you are taking up one use case at a time, broken down in form of stories. Once you have sorted out what all use cases are you dealing with in current sprint or cycle, you can start by understanding logical view for these cases. Moving on to Process view then Development view and finally Physical view, case by case. So rather than creating the whole picture in one go, we will be creating our architecture as and when we are working on a particular use case.