In this series of popular system designs, I will take up design for a taxi aggregator service like Uber. Please note that the designs I share are based on my understanding of these systems and might not be the same as actual designs.
Before Getting on with Designs, let’s list down the requirements
Functional Requirements
User (Rider) should be able to create an account
Driver should be able to register
Rider should be able to view cabs availability in near proximity along with approx ETA
Rider should be able to request for a cab
Driver should be able to receive a trip request.
Driver can accept the request (Assumption: Multiple drivers will receive the request and one will accept)
Trip starts when rider boards the request.
When trip ends, Rider can make the payment and receive a receipt.
Rider can rate the Trip / Driver
Rider can view Trip history
Driver can view Trip history
Non Functional Requirements
Availability
Scalability
Performance
Consistency
Localization
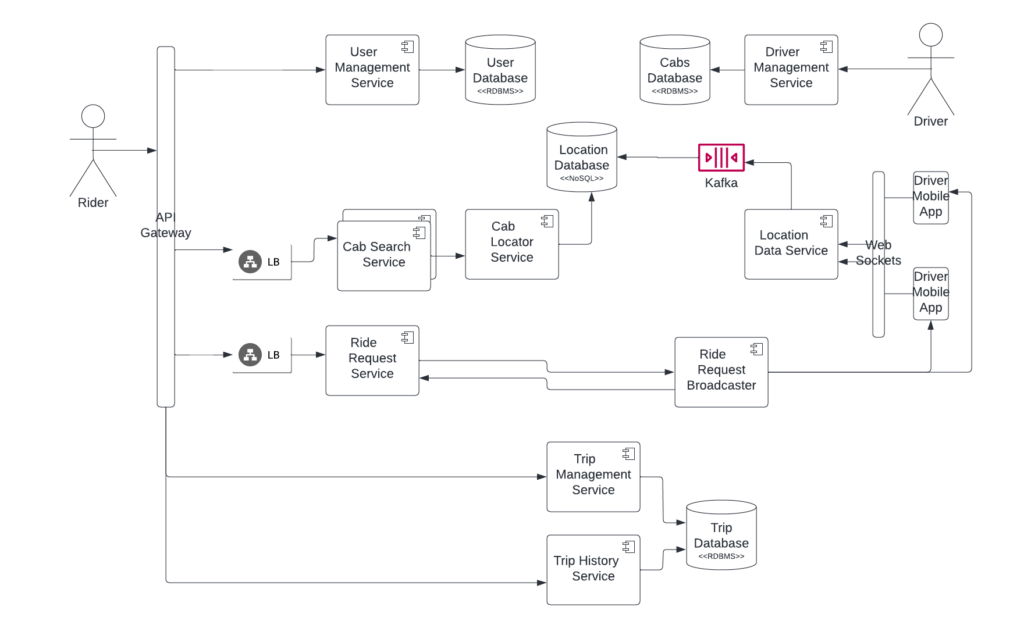
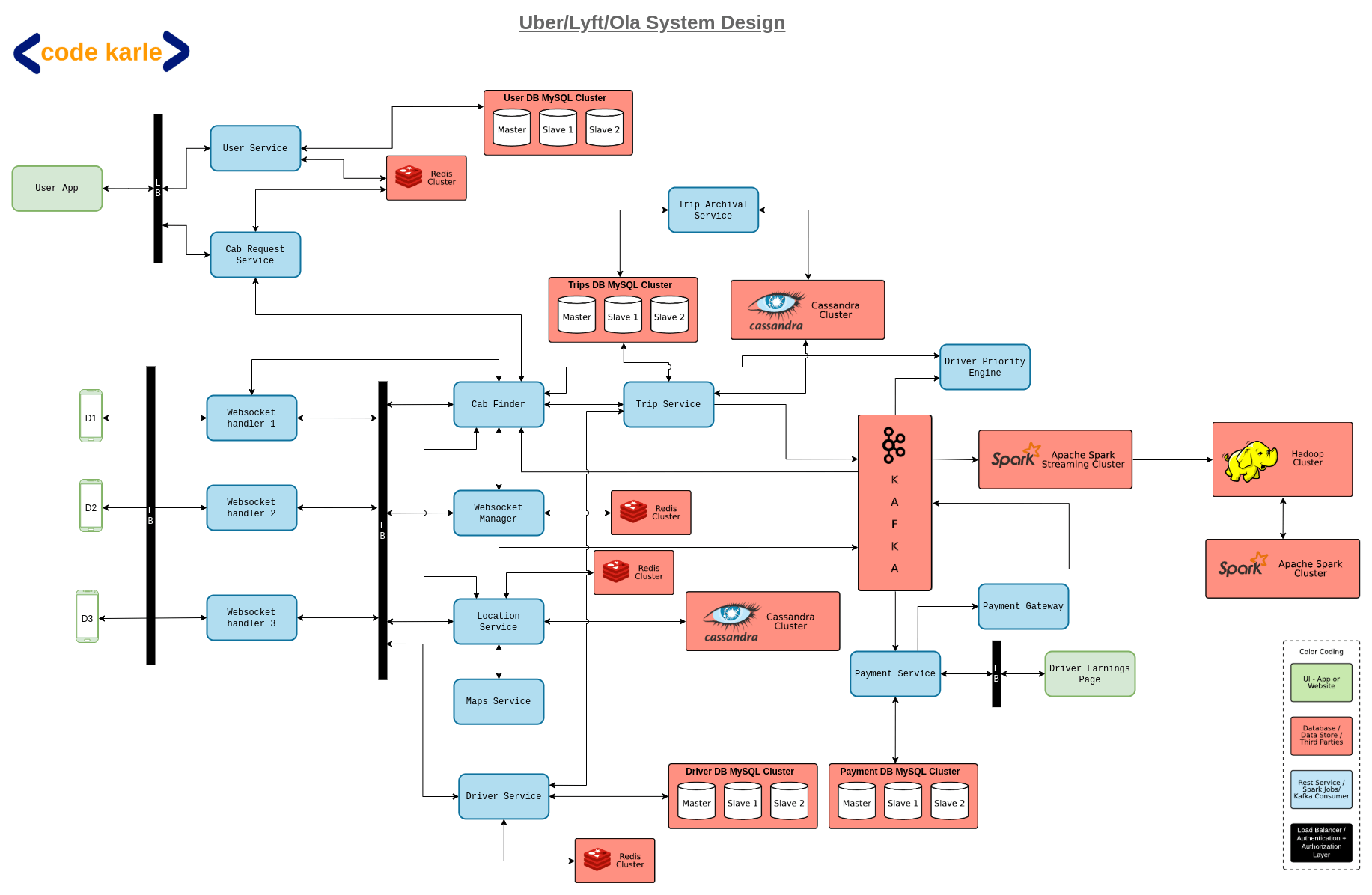
Services to be created
User Management Service
Driver Management Service
Cab Search Service (Takes Riders location and finds nearby cars)
Ride Request Service (Rider’s request is shared with drivers for acceptance)
Trip Management Service
Trip History Service
Database Requirements
User Data
Driver and Cab Data
Cab Location Data
Trip Data (Current and Historical)
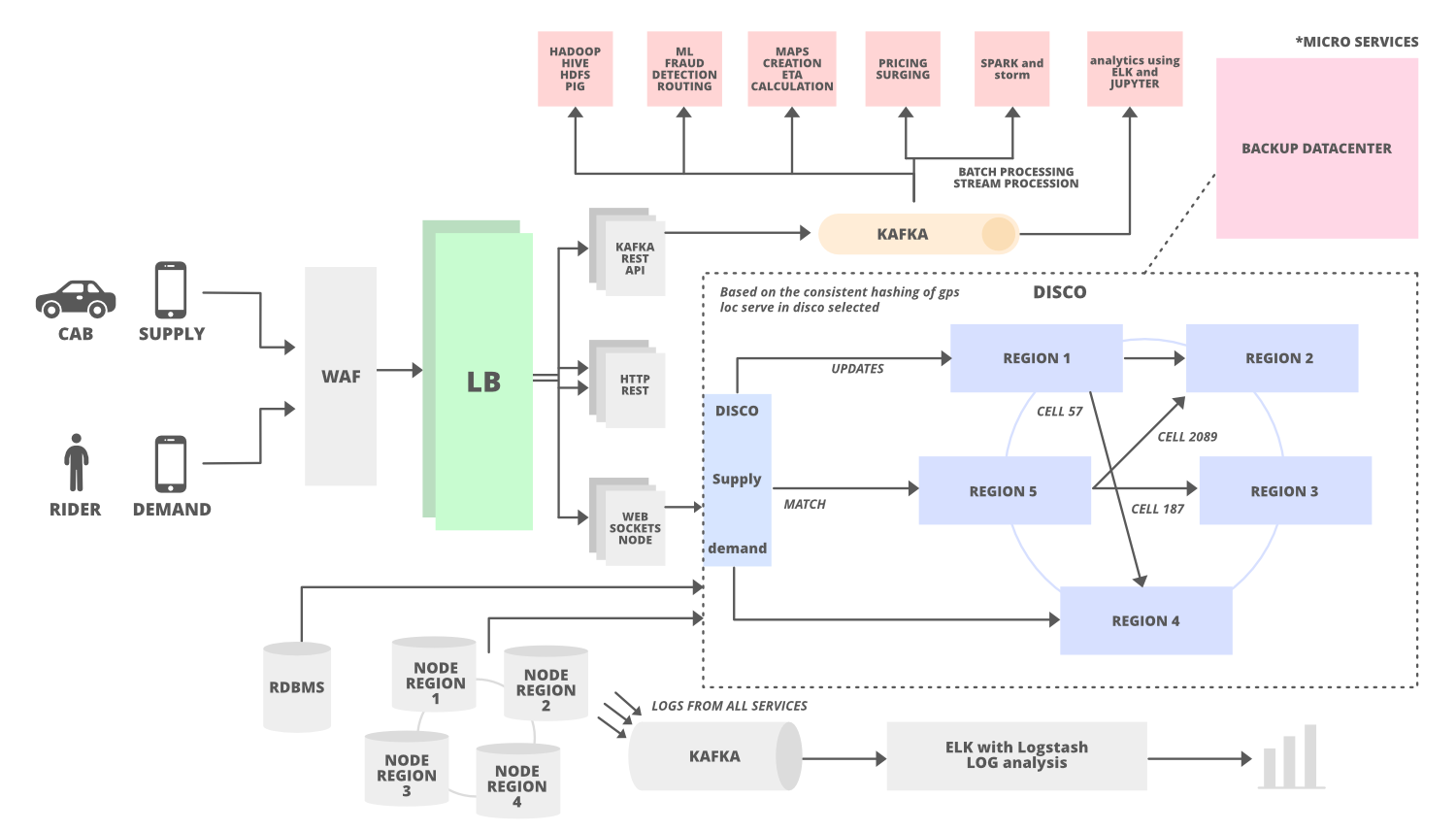
A high-level design might look like
An important question one needs to answer is about the Cab locator service works. The class way of GeoHashing should be used, where the whole area will be thought of as square boxes. Say a user is at Lat, Long position, we will try to find all the boxes around the current location within a given radius. And then find all the Drivers available in these Geo boxes.
Not planning to write yet another article on best practices for REST APIs as the topic is covered multiple times already. What better than Google’s reference document – https://cloud.google.com/apis/design/naming_convention
Here I would like to discuss some cases which are not straightforward. But before going there it makes sense to revise some basic concepts.
REST stands for Representational State Transfer. One can manage state of a resource.
The key abstraction of information in REST is a resource. Any information that we can name can be a resource. For example, a REST resource can be a document or image, a temporal service, a collection of other resources, or a non-virtual object (e.g., a person).
The state of the resource, at any particular time, is known as the resource representation.
The resource representations are consist of:
the data
the metadata describing the data
and the hypermedia links that can help the clients in transition to the next desired state.
When we say REST can help to manage resources (CRUD operations), it is done by following methods
POST for Create
GET for Read
PUT and Patch for update
DELETE for Delete
There are other methods like options and head, but we will focus on the core CRUD operations mentioned above.
To get started let’s take a simple use case, where we have a resource Employee
Generic URL format will look like /{baseurl}/{service or microservice}/{resource}
For example https://api.kamalmeet.com/employee-management/employees
GET list of the employees GET/employees
Get specific data GET/employees/{id}
Create a new object POST/employees
Update an employee object Patch or PUT /employees/{id}
Delete the object DELETE /employees/{id}
Now that was the easy part
Let us talk about some complex cases now, which are not straightforward to fit into REST naming conventions.
Fetch Related resources for the object
/employees/{id}/projects/
Controller verb for a special operation
/users/{id}/cart/checkout
Complex resources representation
only get specific orders (dashes are acceptable)
/users/{id}/pending-orders/
Fetch only specific columns
/employees/?fields={name, department, salary}
Complex searches (reports)
/search/?params={}
/reports/absentreport
Complex listing
/myorders
Above are some of the acceptable practices. Users can modify as per their needs.
Designing or architecting a system is a complex task. One needs to think of various aspects that can impact a system. At a high level, we bucket the requirements into two parts – Functional and Non-Functional. Functional requirements, in simple words, can be thought of as functionalities one needs to build. Non-functional requirements can be complex as they usually will not be called out explicitly and as an architect, you need to figure out after discussions with various stakeholders.
In this post, I would try to look at the system design for Netflix. Of course, it is a complex system and it is difficult to cover in one post, but I will try to touch upon important aspects.
Functional Requirements:
Account Management: Create Account/ Login/ Manage and Delete the Account
Subscription Management
Search
Watch a Video: View/ Download for offline viewing
Recommendations: User-based/ Generic/ Top trends/ Genre
Device Synchronization
Language Selection: Audio/ Video
Non-Functional Requirements:
Performance: Realtime streaming performance
Reliability
Availability
Scalability
Durability
Data needed:
number of users
daily active users
the average number of videos watched per day/ per user
Microservices-based architecture: Netflix is an early adapter of microservices and helped popularize the use of microservices. Microservices help Netflix manage its critical services by keeping them stateless, secured, scalable, available, and reliable.
CDN or Content Delivery Network: In the image above we see Open Connect, which is Netflix’s CDN. For any application which has consumers across multiple geographies, CDN is an important piece. This helps deliver content like images, videos, JavaScript, and other files from a location nearest to the user helping improve performance. In addition, Netflix provides Open Connect Appliances to ISPS free of cost, which helps ISPs save bandwidth and helps Netflix Cache content for better performance.
Transcoding: Any video getting uploaded to Netflix then gets converted to videos of various resolutions. The video gets uploaded to a queue from where it is taken up by transcoder workers who after converting the video upload them to AWS S3. When a user clicks on a video to be played, the best option is chosen based on the client and bandwidth.
API Gateway: ZUUL is the API gateway used by Netflix, which provides features for gateway like security, authentication, routing, decorating requests, Beta testing (based on routing), etc.
Resiliency: It is a resiliency library by Netflix. It handles scenarios like timeout handling, failing fast by rejecting requests when the thread pool is full, circuit breaker when the error rate is heavy, fallback to default response, etc.
Cache: Netflix uses EV cache to provide performance, reduced latency, better throughput, and reduced overall cost. EV cache is a custom implementation of Memcache, which is not dependent on RAM and can use SSD.
Database: Netflix uses MySQL for data that needs ACID properties, data like user data. Read replicas are used to improve query performances. Cassandra is used for NoSQL, to keep data like browsing and watching history. Older history data can be moved to the compressed cheaper data store.
Logs Management: All log data is sent to Chukwa through Kafka. You can view logs on the dashboard. Finally, logs can be sent to S3 for further retention and usage.
Search: Elastic Search is used for indexing and searching.
Recommendations: Spark is used for data analysis. it helps rank content based on user history as well as using data from users with similar tastes. For example, if two users have given similar ratings to a movie, their tastes might be similar. Also if a user watches comedy content mostly, the recommendation engine might suggest more comedy content.
In today’s world, we are always striving for building applications which can adapt to constantly changing needs. We want our systems to flexible, resilient, scalable and withstand end user’s high expectations.
Considering these needs, a Reactive Manifesto was put together, with best practices which will help us build robust applications. Following four pillars makes a strong base of reactive application.
You can see none of these concepts are new in nature, and you might be already implementing them in the applications you build. Reactive Manifesto brings them under one umbrella and emphasizes their importance. Let’s take a look at these pillars one by one and see what all well-known patterns we can use to implement each of them.
Responsive: An application is responsive if it responds to the user in a timely manner. A very simple example is you clicked on a button or link in a web application, it does not give you a feedback that button was clicked and the action gets completed after few seconds. Such an application is non-responsive as the user is left guessing if he is performing the right action.
Some of the well-known practices and design patterns which help us make sure if the application is responsive
– Asynchronous communication
– Caching
– Fanout and quickest reply pattern
– Fail-fast pattern
Resilience: An application is called resilient if it can handle failure conditions in a graceful manner.
Some of the patterns that help maintain resilience
– Circuit breaker pattern
– Failure handling pattern
– Bounded Queue Pattern
– Bulkhead Pattern
Elasticity: An application is called elastic if it can stand increase or decrease in load without any major impact on overall working and performance.
Some of the practices and patterns to implement elasticity
– Single responsibility
– Statelessness
– Autoscaling
– Self-containment
Message Driven: An application which uses message driven communication makes sure we are implementing various components and services in a loosely coupled manner. This helps us keep our components scalable and makes failure handling easy.
Practices used to implement Message driven communicaiton
– Event driven
– Publisher Subscriber pattern
– Idempotency pattern
Somehow, with the penetration of agile development practices, I have been observing that less and less time is spent on designing the solution. Engineers treat Agile as a license to develop without design.
What is the problem with developing without designing or architecting the system first? I still remember when I was in college, my professor drew a parallel between architecting a building and architecting a software. Would you start building a house without thinking about design? you will not just start placing bricks without considering how many rooms you need? Where all these rooms go? How large should be every room? Where will the kitchen and bathroom be? Where all the wiring and plumbing will go? You will come up with the design, put in on a paper or a software and then calculate the feasibility.
Think of the complications that can happen if you build your house without thinking about design first. One room might be so big that there is very little space for the others. Or you are not left with any space to create a bathroom. These mistakes are costly. And that brings me to the other important factor which is causes ignoring of design in software. The manager thinks that change at a later state is going to be easy. At the end it is code, we can just change it. Well, changing the code is definitely possible, but never easy or cheap. It comes with its own cost.
More than often, where developers need to make changes at a later stage, they would be more inclined to apply quick fixes or hacks rather than making a bigger correct change. Of course, you have a tried and tested code in hand, why would you make too many changes to it, even if you know that is the right thing. And then there is developer ego, I mean, let’s admit it, it is not easy to accept one’s fault, especially if that means you would need to put in extra hours to fix that. More than ego, it is actually denial at times. People would try to stick to the solution they developed initially even though it is realized at a later stage that there could have been a better solution. Reason being, you have already invested too much.
This situation can be avoided if we think about design first. We can make sure our design covers all the possible requirements. It will not be possible to anticipate all the changes that are going to come at a later stage, but we can try to keep our design flexible. The idea is, set the ground rules, understand what all component and services we are required to create? What all data needs to be persisted and how are we going to do that? How security and error handling will be done? We need not get into implementation details, but the high-level design is a good start. We can fill in the details as and when requirements are clearer and we start actual work on the given piece of requirement.
In the end, all I would like to highlight is, if you think you are saving time by not thinking about the design of the application before you start to code, you are going to end up spending more time applying patches and fixes at the end.
When developing high level design for a solution, it is not a good idea to think about technology choices. We need to keep a gap between design and implementation.
You should not finalize at this point if the solution is going to be build in Java, Python, NodeJS or PHP at this time. For example, you just define that there will be a employee service to provide employee data, but which language will be used to build it, is not part of high level design.
You should take a call what kind of database is well suited, will it be a RDBMS or a document based database, but we should not take a decision which specific vendor’s database we are going to use at this point. For example, we will take a call that we will use RDBMS, but will it be Oracle, mySQL, postgres or some other vendor provided DB, we will decide when we will think about implementation details.
Similarly, all your vendor and technology decisions will not be part of high level design. The details should be filled at a later point, once you have finalized your high level design and made sure you have all the components, services and communications identified.
Why should we not think about technology choices while building high level design? Because it limits our design and solution. Because strengths and weaknesses of a technology becomes strength and weakness of our solution. Because strengths and weaknesses of technologies change over time, hence our architecture should be independent of that.
Once you bring in vendor and technology at a high level design, you commit too much to that. For example say XYZ RDBMS provider is currently the best in market as they provide fastest operations. You design your architecture around that, you use vendor specific data structures and data types. In future, if there is a vendor providing similar services at a cheaper price, we will figure out making a change is very costly as we have to change too much of code. If we would have thought of RDBMS as just a plug and play provide, we could have made this change easily. Infact, keeping our architecture technology agnostic will force us to think beyond a vendor. We will need to think ways of improving our database performance, think of better indexing, sharding, caching, making our architecture robust and independent of technology and vendors.
There are many best practices and principles figured out by developers and architects for object oriented design. Robert Martin has intelligently put a subset of these good practices together, and gave them acronym SOLID which helps easy remembrance.
Single responsibility principle: A class should handle only one single responsibility and have only one reason for change. For example a class “Employee” should not change if there a change in project or some reporting details.
Open Closed principle: Code should be open for extension but closed for modification. If you want to add a new type of report in the system, you should not be changing any existing code. More here
Liskov substitution principle: “objects in a program should be replaceable with instances of their subtypes without altering the correctness of that program.” So if we have Employee class, which is extended by Manager. We should be able to use Manager instead of Employee and all the Employee methods like calculate Salary, generate annual report etc should work without any issues. Say if there is an object like “ContractWorker” that does not support a few functions of Employee like annual report, one should be careful not to make it subtype of Employee.
Interface Segregation principle: “no client should be forced to depend on methods it does not use”. Coming back to previous example, if “ContractWorker” does not need to support annual report, we should not force it to implement an iEmployee interface. We should break the interfaces say iReport and iEmployee, iEmployee can extent iReport and iContractWorker should implement only iReport. iReport can further be divided into reporting types if required.
Dependency Inversion principle: This one seems to be one of my favorite as I have written about it here, here, here and here. This one indeed is one of the most important design patterns which can be followed to make the code loosely coupled and hence making it more maintainable (golden rule- low coupling + high cohesiveness). In traditional programming, when a high level method calls a low level method, it needs to be aware of the low level method at compile time, whereas using DI we can make high level method depend on an abstraction or interface and details of implementation will be provided at run time, hence giving us freedom to use which implementation to be used. Coming back to my previous example, I can have multiple implementations of Employee Reporting, iReport. Some implementation need and excel report, other might need a PDF reporting, which can be decided at runtime.
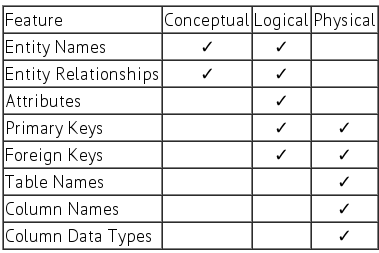
When you are designing database for an application, there can be 3 core levels at which you can design your database.
1. Conceptual Level: At this level you are only aware of high level entities and their relationships. For example you know that you have “Employee” Entity who “works for” a “Department” and “has” an “Address”. You are not worried about details.
2. Logical Level: You try to add as much details as possible, without worrying about how it will actually be converted to a physical database structure. So will provide any attributes for “Employee” i.e. Id, FirstName, LastName, AddressId, Salary and define primary and foreign key relations.
3. Physical Level: This is the actual representation of your database design with exact column names, types etc.
DbVisualizer A simple tool to generate ER diagram if you have existing database on system.
1. Download and install the tool
2. Open and create a new connection by choosing database type, credentials etc.
3. Select schema, go to Tables->References.
4. Export the ER diagram.