Edge Computing takes distributed computing close to the information source, rather than relying on centralized data centers. This approach is relatively popular for systems that involve IOT devices.
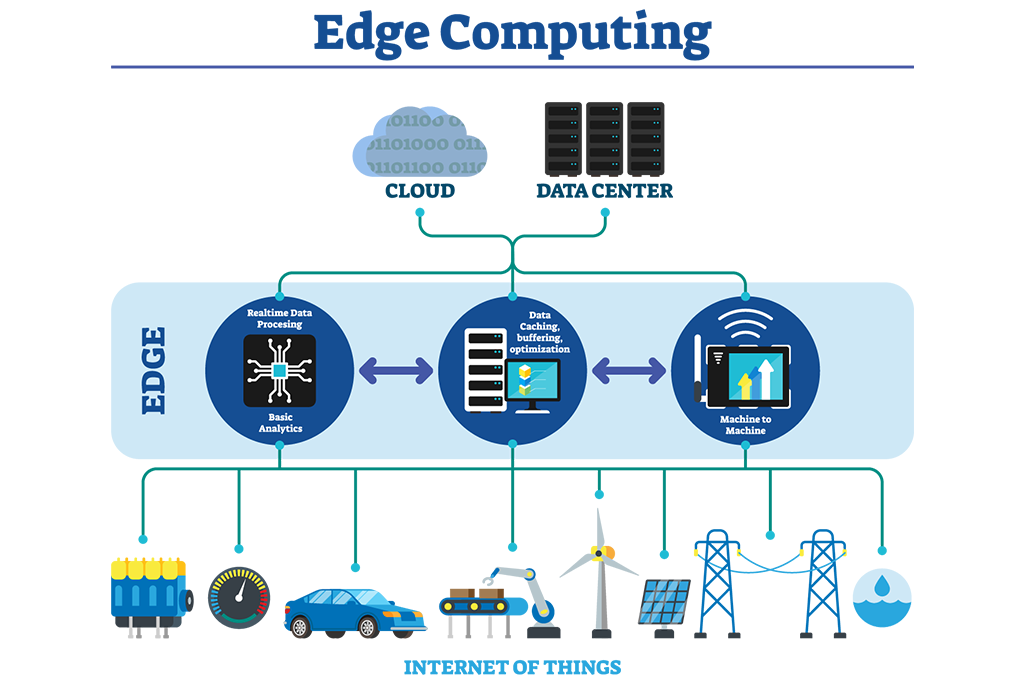
The idea is to keep computation near to source, to reduce latency. Decisions can be made faster as data does not need to be sent to long distance. This also reduce the amount of data sent to central servers as some level of data filtering and analysis is pre-processed at edge locations.
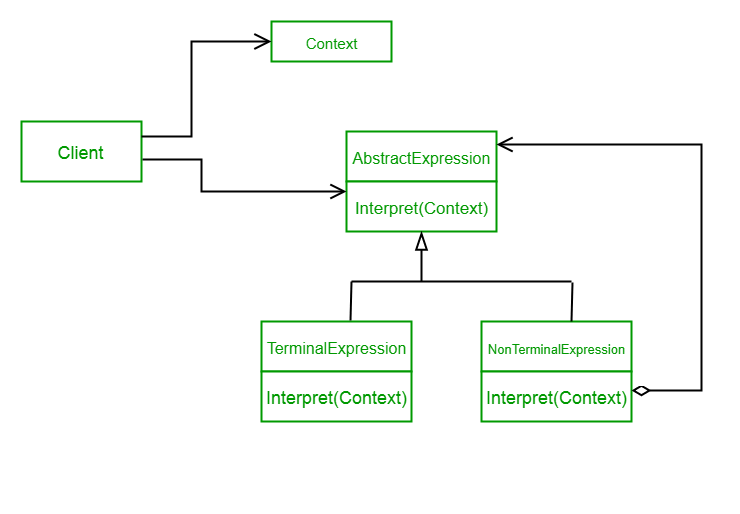
Edge Computing architecture usually contains following components
- Edge devices: Devices that collect data from sensors, cameras, and other sources. Examples include IoT devices, cameras, and industrial equipment.
- Edge gateway: An edge gateway acts as a bridge between the edge devices and the back-end systems.
- Edge server: This is a server located at the edge of the network that is responsible for processing and analyzing data. It can run applications and services that are optimized for low-latency and high-performance requirements.
- Fog nodes: These are intermediate devices that sit between the edge devices and the cloud or data center. They are responsible for processing and analyzing data, similar to edge servers, but they are typically more powerful and capable of running more complex applications and services.
- Cloud/Data center: The data that is processed at the edge is then sent to a cloud or data center for further analysis, storage and sharing.
- Management and orchestration platform: This is a platform that manages and monitors the edge devices, gateways and servers, and allows for the deployment, configuration, and management of edge applications and services.