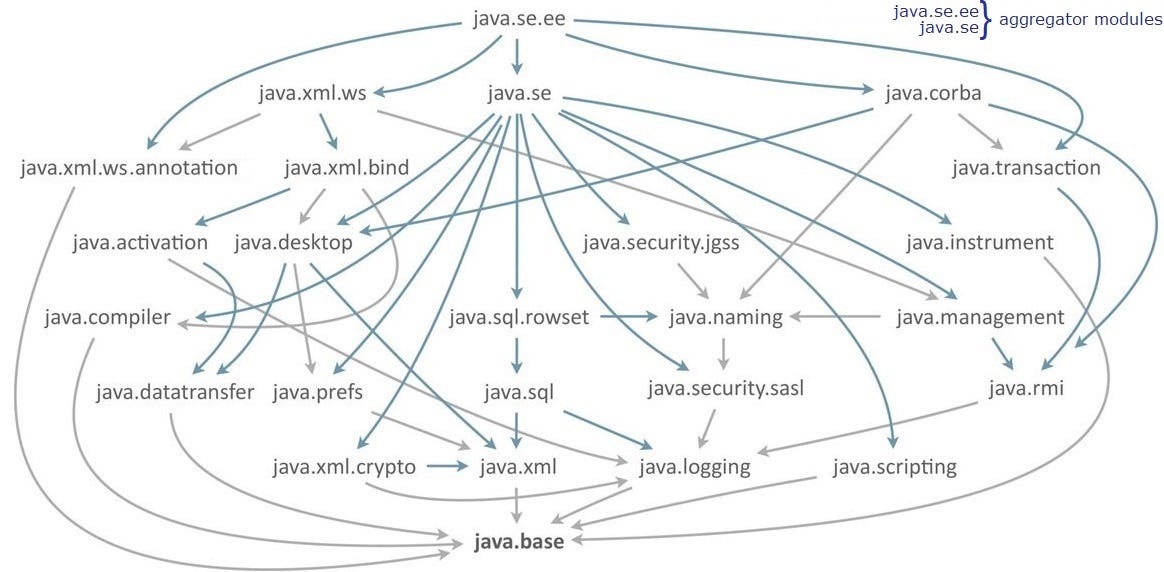
Modularization introduced in Java 9 is to help developers call out explicitly what are they going to use in their application and what features are they ready to expose.
You can see that JDK itself now is viewed as a combination of modules rather than a single monolith unit. One can mention all modules they are going to use in the application and keep the application lightweight. This can be done by adding a “requires” section in the module-info file.
Another problem Modules solve is when you are sharing your library (a jar), it exposes all the packages, though you might not want users to play around with internal helper files. The “exports” keyword gives you control over what is being exposed from the package.
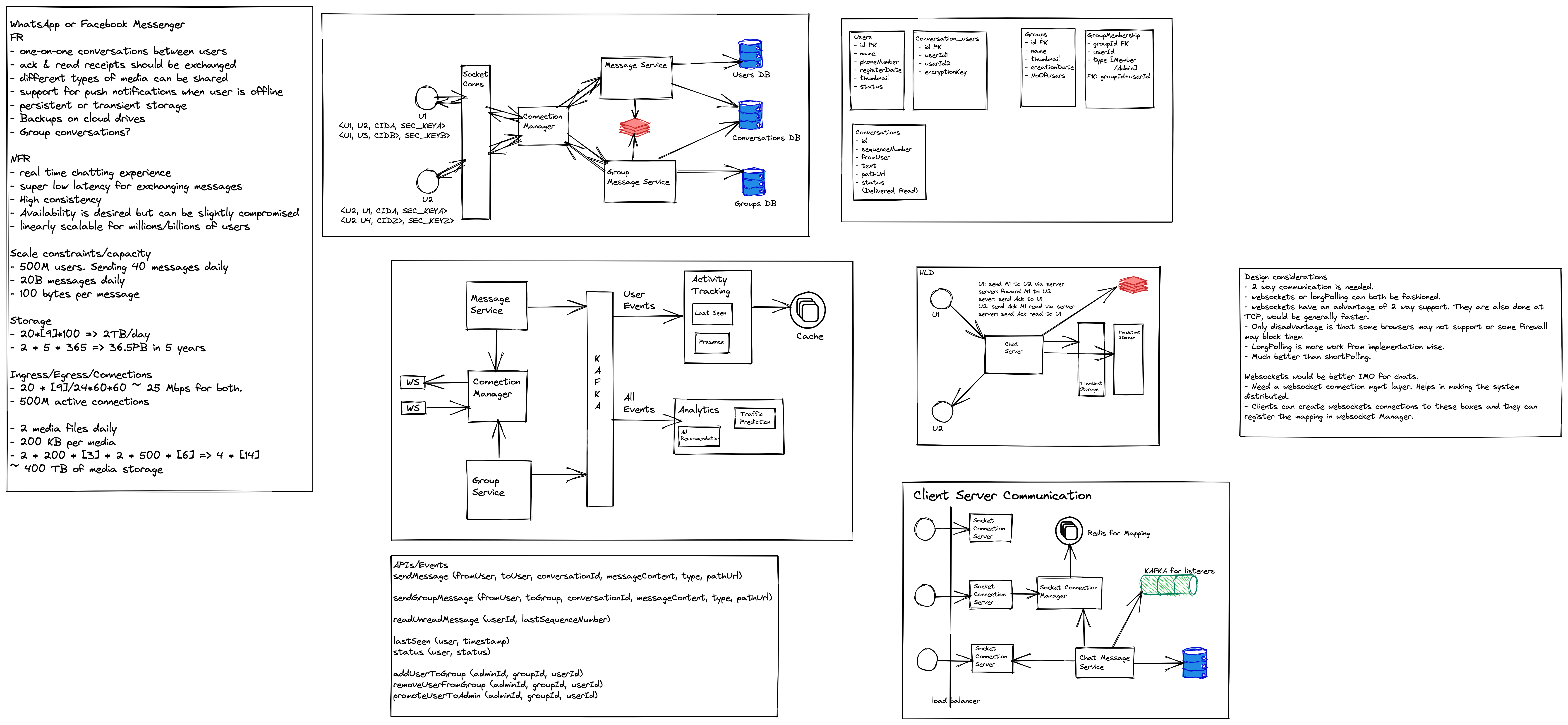
In this series of trying to understand designs for popular systems, I am taking up Whatsapp in this post. Please remember all the designs I am sharing in this series are my personal view for educational purposes and might not be the same as actual implementation.
To get started let us take a look at the requirements
Functional Requirements
User should be able to create and manage an account (Covered already)
User should be able to send a message to contact
User should be able to send a message to a group
User should be able to send a media message (image/ video)
Message Received and Message Read receipts to sender
Voice Calling (Not covering here)
Non Functional Requirements
Encryption
Scaleability
Availability
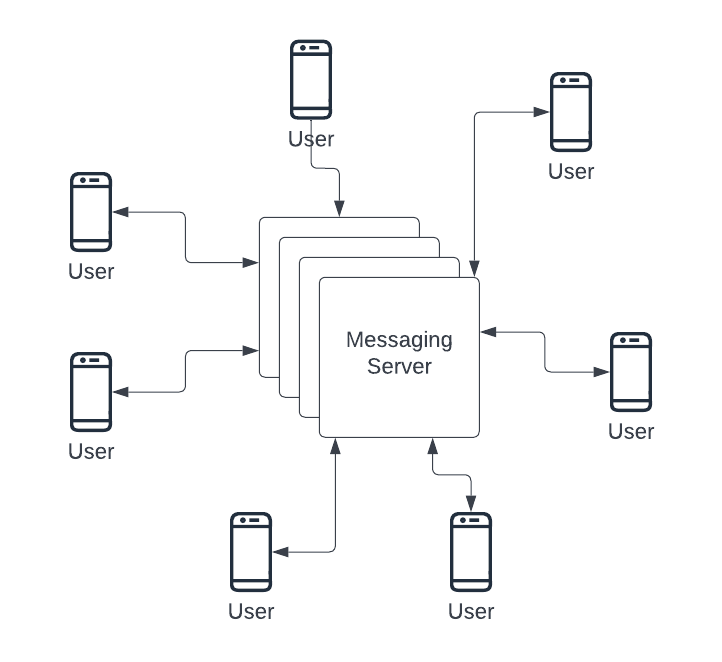
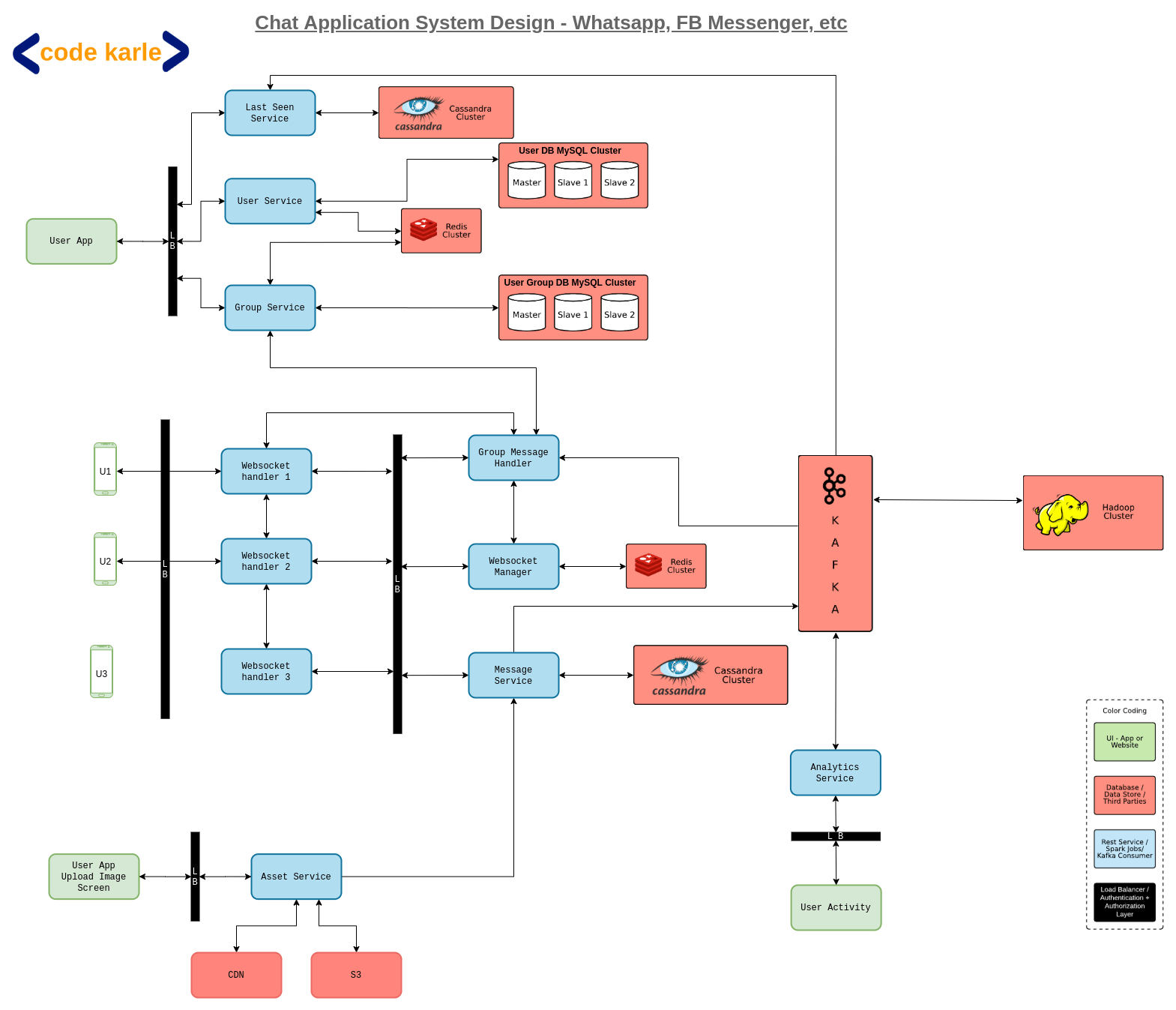
At a very high level, the design looks very straightforward
The first important thing that we see here is that communication is not one-way like a normal web application where the client sends a request and receives a response. Here the mobile app (client) should be able to receive live messages from the messaging server as well. This kind of communication is called Duplex-Connection where both parties can send messages. To achieve this, one can use long polling or web sockets (preferred).
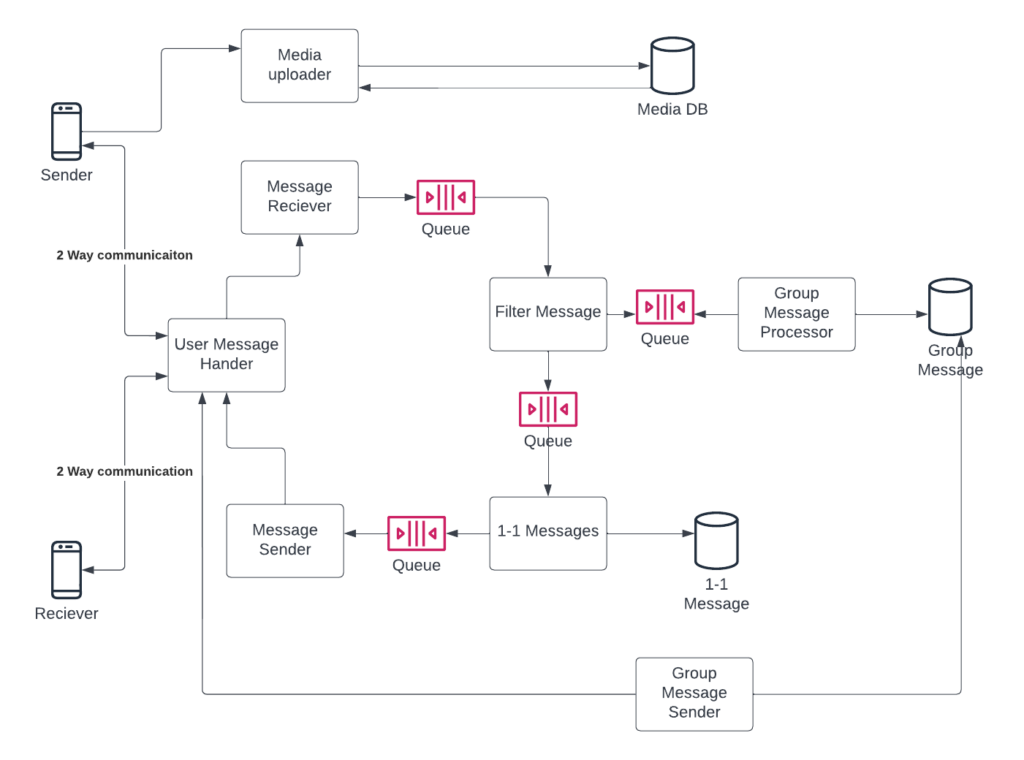
Communication Management: When a user sends a message, it will be sent to the queue of messages received, from where it will be processed and sent to the queue for messages to be sent to users.
Media Management: Before sending the message for processing, media is uploaded and stored in a storage bucket, and the link is shared with users, which can be used to fetch the actual media file.
Single/ Double/ Blue Tick: When a message is received and processed by the server, the information is sent back to the user and marked single ticked. Similarly, when the message is sent successfully the receiver is marked double tick and finally, when the receiver opens the message, it is blue ticked for the sender.
The problem we are trying to solve is to create a service that can take a large URL and return a shorter version, for example, say take https://kamalmeet.com/cloud-computing/cloud-native-application-design-12-factor-application/ as input and give me https://myurl.com/xc12B2d, a URL easy to share.
The application looks simple, but it does provide a few interesting aspects.
Database: The Main database will be used to store long URLs, short URLs, created dates, created by, last used, etc. as we can see this will be a read-heavy database and should be able to handle large datasets, a NoSQL document-based database should be good for scalability.
Data Scale:
Long URL – 2 KB (2048 chars)
Short URL – 7 bytes (7 chars)
Created at – 7 bytes (7 chars for epoch time)
last used – 7 bytes
created by – 16 bytes (userid)
Total: ~2KB
2KB * 30 million URLs per month = ~60 GB per month or 7.2 TB in 10 years
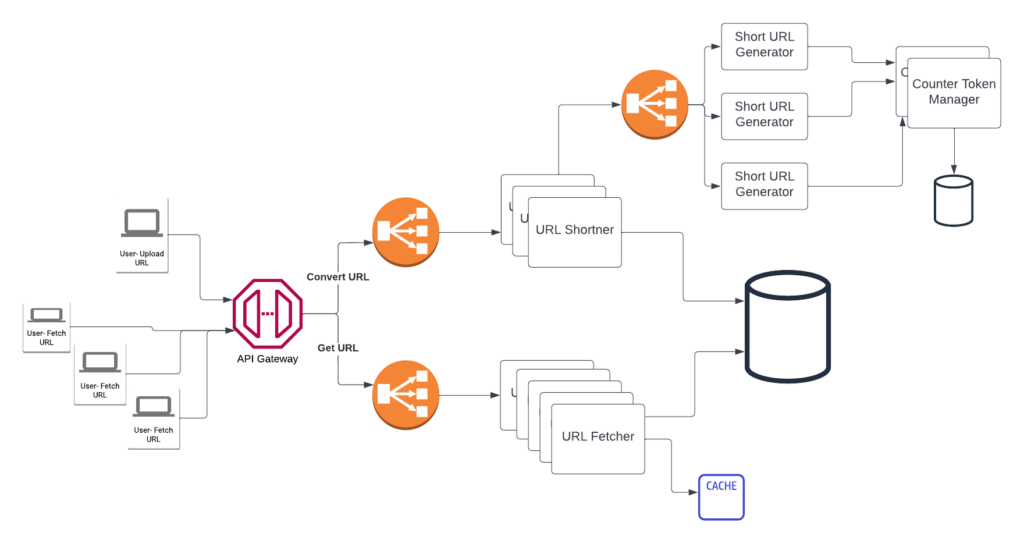
Format: The next challenge is to decide the format of the tiny URL. The decision is an easy one, Base 10 URL would give you 10^7 or 10 million combinations for a 7-character string whereas a Base 62 format will give 62^7 or 3.5 trillion combinations for 7 character string.
Short URL Generator: Another challenge to solve is how to choose a random 7 Base 62 string for each URL.
Soln 1: Use MD5 which returns a string of 20+ chars, we can take the first 7 characters. The problem here is taking the first 7 characters might lead to a collision where multiple strings have MD5 with the same first 7 characters
Soln 2: Use a counter-based approach. A counter service will generate the counter which gets converted to Base 62, making sure all requests get a unique Base 62 string. To scale it better, we will have a distributed counter generator.
Java 8 arguably is the most common of the Java versions and I see many projects still use Java 8. Among many other features, two of the essential elements released with Java 8 were Lambda expressions and streams. Here are some old notes recap on these topics.
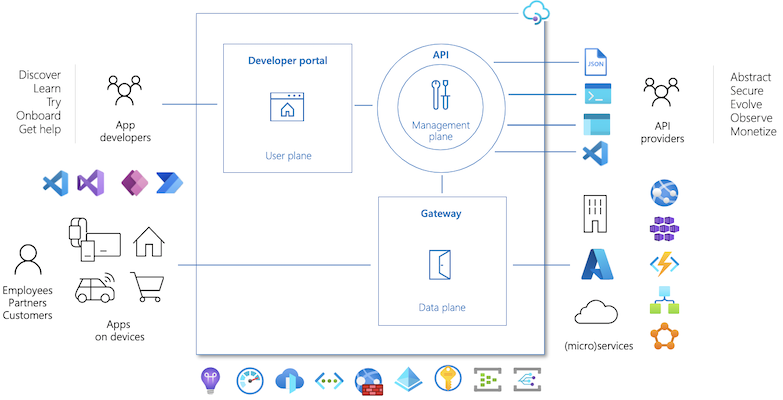
Azure API Management provides a set of services that can help users to manage API Lifecycle, i.e. Design. Mock, Deploy, Policy Management, Explore, Consume, and Monitor APIs.
we can see there are three core components here. Developer portal helping consumers to discover, try out and onboard to services. Management Plane helps providers manage the API policies and monitor them. The gateway is the interface between consumer clients and provider applications.
API Gateway
The API gateway acts as a facade to the backend services, allowing API providers to abstract API implementations and evolve backend architecture without impacting API consumers. The gateway enables consistent configuration of routing, security, throttling, caching, and observability.
To create API Gateway, you will need to go to Azure Portal -> API Management Service -> Create
Management Plane
API providers interact with the service through the management plane, which provides full access to the API Management service capabilities. Customers interact with the management plane through Azure tools including the Azure portal, Azure PowerShell, Azure CLI, a Visual Studio Code extension, or client SDKs in several popular programming languages.
If Gateway was about implementing policies in real-time, Management plane is about helping developers set these policies and interact with analytics dashboards via portal VC Code extension or other Azure interfaces.
Developer Portal
App developers use the open-source developer portal to discover the APIs, onboard to use them, and learn how to consume them in applications.
User is able to upload or download files via a client application or web application
User is able to sync and share files
User is able to view the history of updates
Non Functional Requirements
Performance: Low latency while uploading the files
Availability
Concurrency: Multiple users are able to update the same file
Scaling Assumptions
Average size file – say 200 MB
Total user base- 500 million
Daily active users- 100 million
Daily file creations- 10 per user
Total files per user- 100
Average Ingress per day: 10 * 100 million * 200 MB = 200 petabytes per day
Services Needed
User management Service
File Handler Service
Notification Service
Synchronization Service
File Sync
When Syncing the files we will break the file into smaller chunks, so that only the chunk which has undergone updates will be sent to the server. This architecture is helpful in contrast to sending the file to the server for every update. Say a 40 MB file gets broken into 2 MB chunks each.
This architecture helps solve problems like
Concurrency: If two users are updating different chunks, there is no conflict
Latency: Faster and parallel upload
Bandwidth: Only chunk updated is sent
History Storage: New version only need a chunk of data rather than full file space
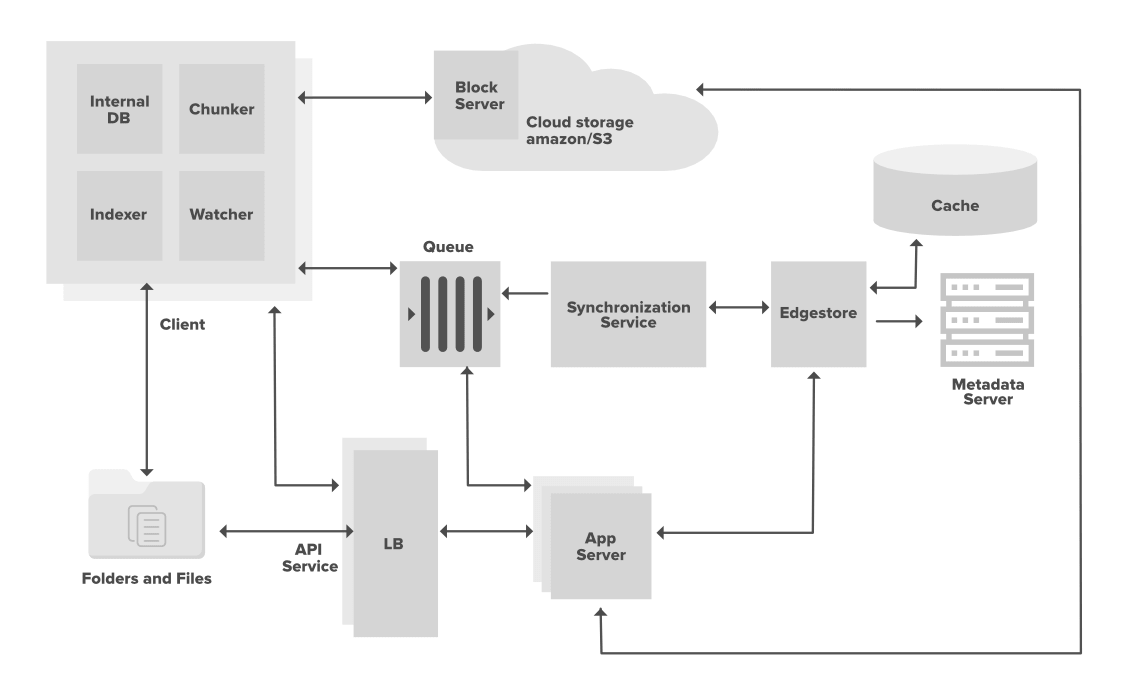
The most important part of this design is the client component.
Watcher: This component keeps an eye on a local folder for any changes. It informs Chunker and Indexer about changes.
Chunker: As discussed above, the chunker is responsible for breaking a file into manageable chunks
Indexer: On receiving an update from watcher, Indexer updates the internal database with metadata details. It also communicates with Synchrnozation service sending or receiving information on updates happening to files and syncing the latest version.
Internal DB: To maintain file metadata locally on the client.
Cloud Storage finally stores the files and updates. Metadata server maintains metadata and helps inform clients about any updates through synchronization service. Synchronization service adds data to the queue which is then picked by various clients based on availability (if a client is offline, it can read messages later and sync up the data). Edge store helps provide details to clients from the nearest location.
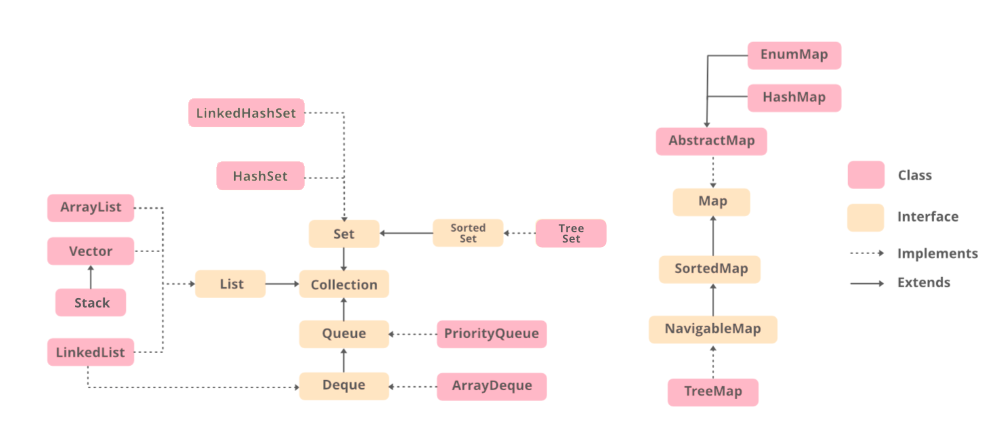
ArrayDequeue: Double-ended queue implementation. Provides methods like add, addFirst, addLast.
Set Implementations
HashSet: Implementation of hash table data structure. Do not guarantee order.
LinkedHashSet: Uses a doubly linked list and hence maintains the order.
Sorted Set Implementation
TreeSet: Ordering is maintained as natural order or explicit comparator based ordering.
publicclass TreeSetDemo {
publicstaticvoid main(String args[])
{
TreeSet<String> ts = new TreeSet<String>();
ts.add("this");
ts.add("is");
ts.add("just");
ts.add("a");
ts.add("test");
Iterator<String> itr = ts.iterator();
while (itr.hasNext()) {
System.out.println(itr.next());
}
}
}
Output
a
is
just
test
this
In this series of popular system designs, I will take up design for a taxi aggregator service like Uber. Please note that the designs I share are based on my understanding of these systems and might not be the same as actual designs.
Before Getting on with Designs, let’s list down the requirements
Functional Requirements
User (Rider) should be able to create an account
Driver should be able to register
Rider should be able to view cabs availability in near proximity along with approx ETA
Rider should be able to request for a cab
Driver should be able to receive a trip request.
Driver can accept the request (Assumption: Multiple drivers will receive the request and one will accept)
Trip starts when rider boards the request.
When trip ends, Rider can make the payment and receive a receipt.
Rider can rate the Trip / Driver
Rider can view Trip history
Driver can view Trip history
Non Functional Requirements
Availability
Scalability
Performance
Consistency
Localization
Services to be created
User Management Service
Driver Management Service
Cab Search Service (Takes Riders location and finds nearby cars)
Ride Request Service (Rider’s request is shared with drivers for acceptance)
Trip Management Service
Trip History Service
Database Requirements
User Data
Driver and Cab Data
Cab Location Data
Trip Data (Current and Historical)
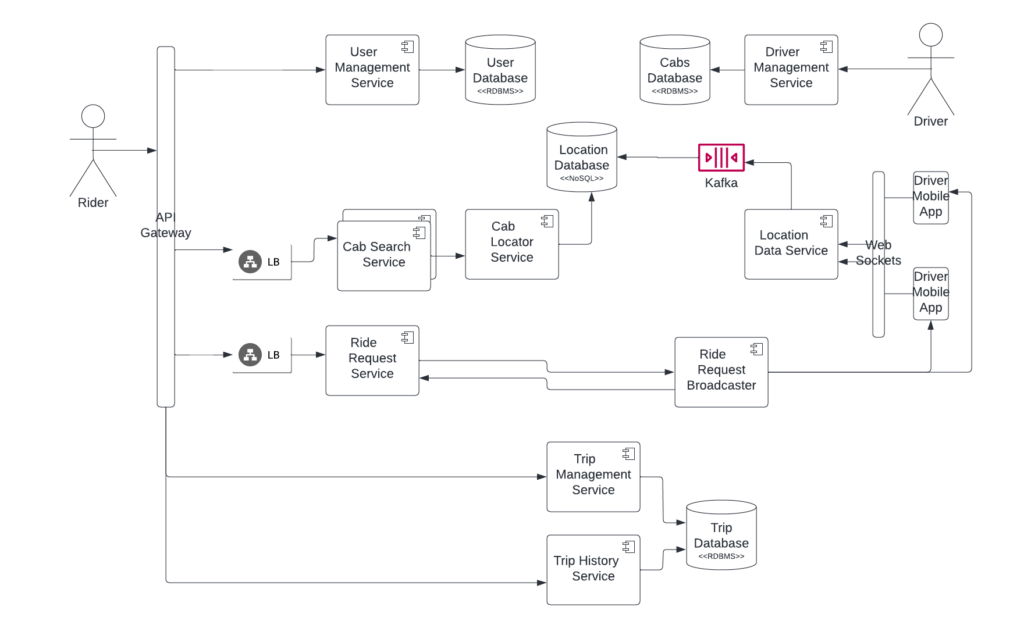
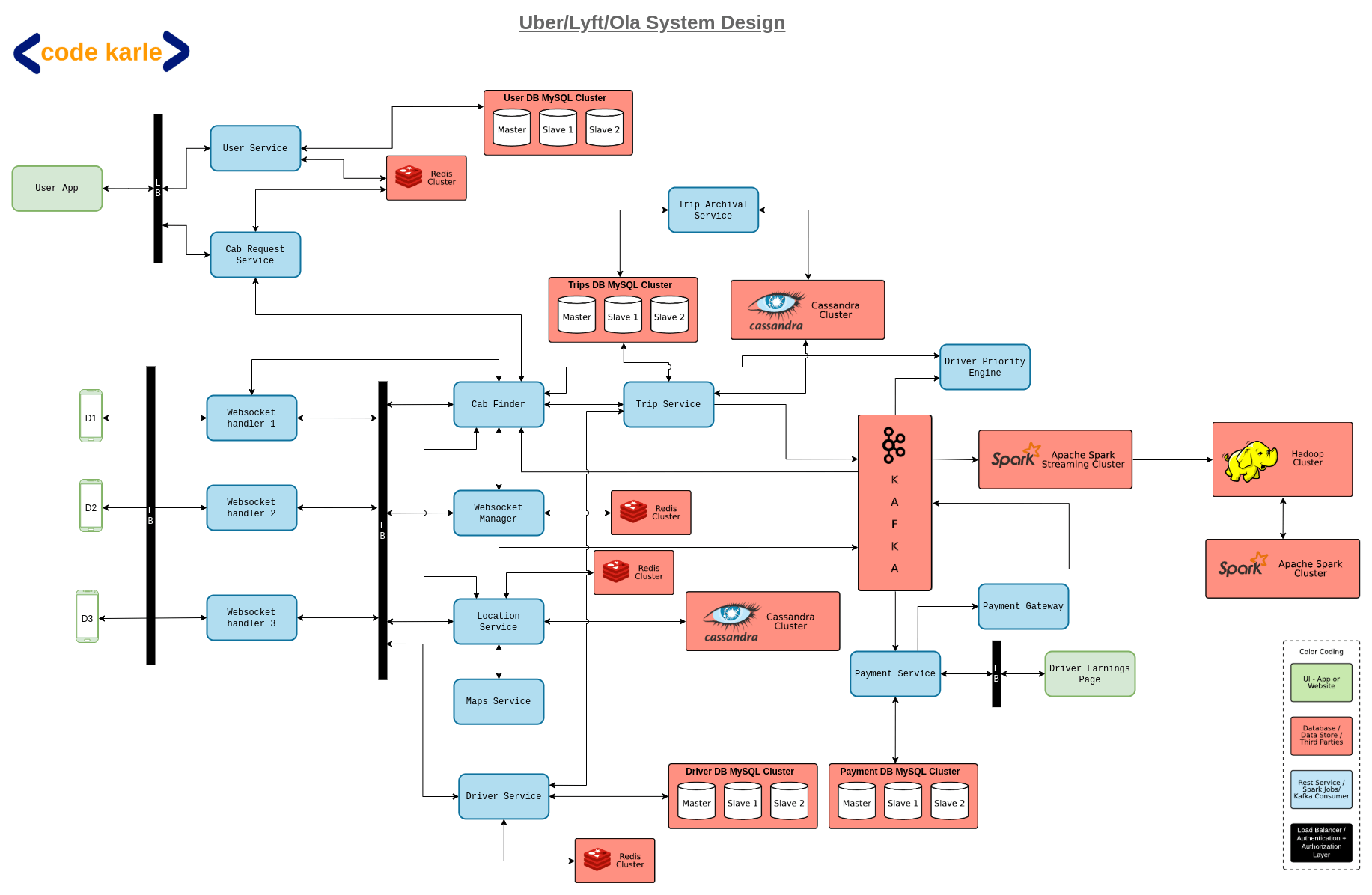
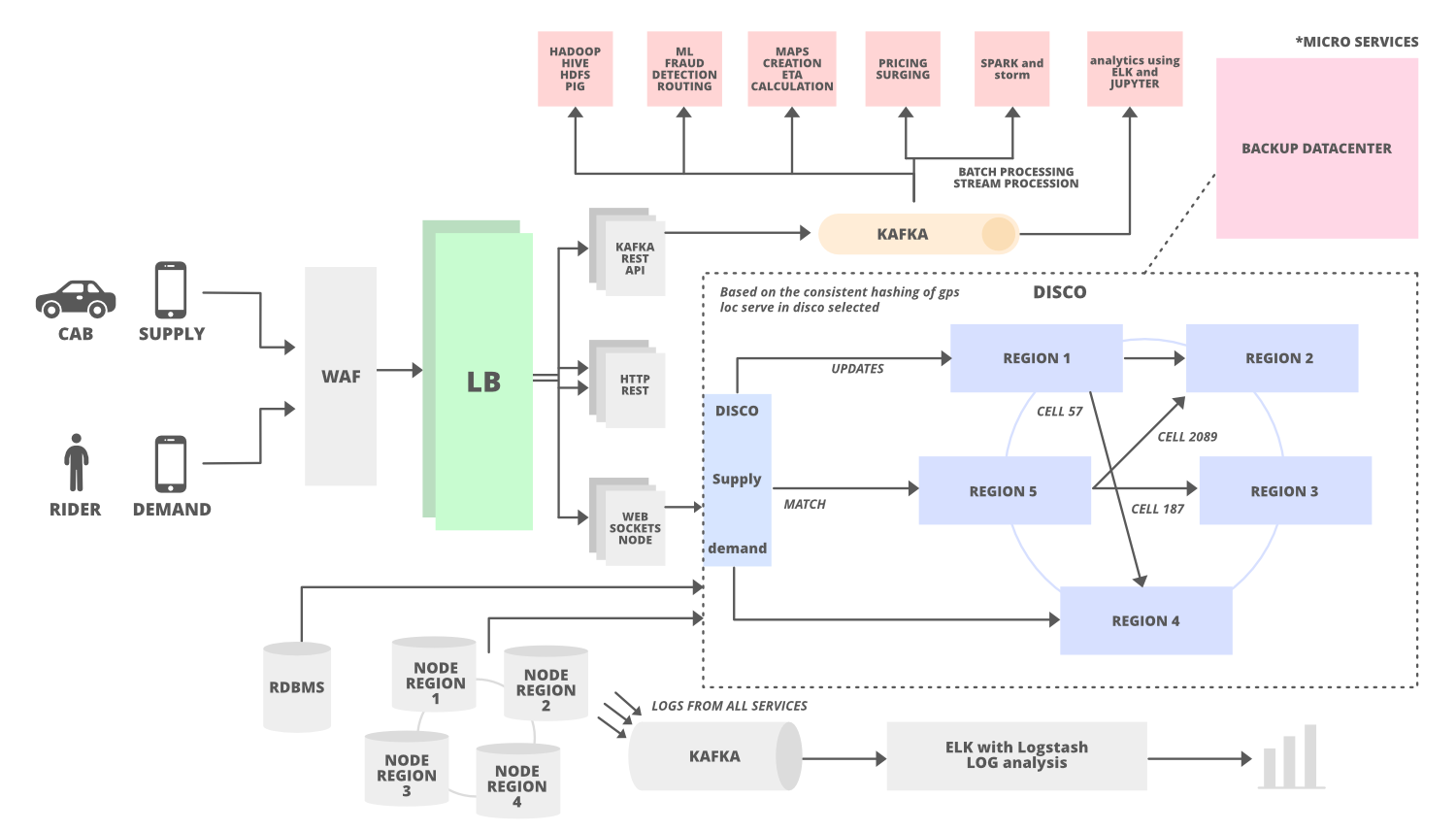
A high-level design might look like
An important question one needs to answer is about the Cab locator service works. The class way of GeoHashing should be used, where the whole area will be thought of as square boxes. Say a user is at Lat, Long position, we will try to find all the boxes around the current location within a given radius. And then find all the Drivers available in these Geo boxes.
When working with applications for which frontend is available in more than one medium, for example, a desktop and a mobile application. The scenario can be complicated when the Application has different mobile versions for Android and iOS. Also, the APIs might be consumed by third-party services. In short, the same set of APIs has other consumers, which might have different requirements out of them.
One way to solve the problem is that the API being called checks the source of the call and replies with the required data for example for a GET orderdetails call, a mobile call might need just order history listing, whereas a desktop frontend might want to show more information as it can accommodate more on the interface. At the same time, we just want to expose a piece of limited information to a third party caller.
If you will look around you will find many sets of best practices available for creating web applications, microservices, cloud-native applications, and so on. Developers and teams generally tend to share their learnings while they have gone through the process of application development. One needs to understand, learn and figure out what one can use in our application development process.
One such list of best practices, which is very popular among developers and architects is “The twelve-factor app”. https://12factor.net/ There are definitely some interesting points in this, that we should understand and use.
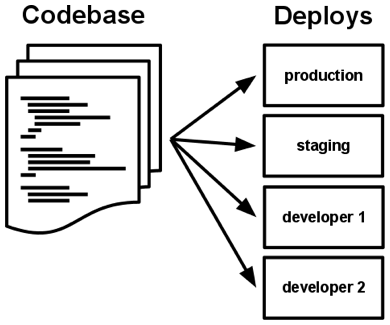
I. Codebase One codebase tracked in revision control, many deploys
Always track your application via the version control system Each microservice should be in its own repository One repository serves multiple deployments e.g. dev, stage, and prod
II. Dependencies Explicitly declare and isolate dependencies
An application has different dependencies to make it work, these can be libraries (jar files), third-party services, databases, etc. You must have seen scenarios where the application is behaving differently on two machines and eventually it is figured out the problem was a different version of a library on the machines.
The idea here is to call out all dependencies explicitly (dependency managers like maven, property files for any third-party dependencies), and isolate them from the main code, so that any developer now can start with a bare minimum setup (say install only Java on the machine) and get started (all dependencies are managed and downloaded separately).
III. Config Store config in the environment
Your application has environment-specific configurations (dev, stage, and prod) like database, caching config, etc.
Keeping configurations with code can have multiple issues
you need to update the code and deploy for any configuration changes
As the access to code will be with most of the developers, it will be difficult to keep control of who can make changes and prone to human errors
To avoid these we will need to keep configurations within the environment.
IV. Backing services Treat backing services as attached resources
Backing services can be databases, storage, message queues, etc. Treating them as resources means that we can replace them easily for example moving from rabitMQ to ActiveMQ
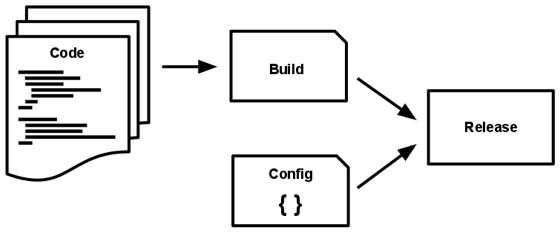
V. Build, release, run Strictly separate build and run stages
Clearly define and separate stages
Build: Results in deployable like war, jar, or ear file that can be deployed to an environment Release: Club build deliverables with environment-specific configuration to create a release Run: A Release is run, e.g. a docker image is deployed on a container.
VI. Processes Execute the app as one or more stateless processes
Look at your application as a stateless process. Imagine the pain maintaining the status for a scalable application (sticky session will hinder true scalability) So make sure to outsource session management
VII. Port binding Export services via port binding
“The twelve-factor app is completely self-contained and does not rely on runtime injection of a webserver into the execution environment to create a web-facing service. The web app exports HTTP as a service by binding to a port, and listening to requests coming in on that port.”
“The process model truly shines when it comes time to scale out. The share-nothing, horizontally partitionable nature of twelve-factor app processes means that adding more concurrency is a simple and reliable operation. “
IX. Disposability Maximize robustness with fast startup and graceful shutdown
“The twelve-factor app’s processes are disposable, meaning they can be started or stopped at a moment’s notice. This facilitates fast elastic scaling, rapid deployment of code or config changes, and robustness of production deploys.”
X. Dev/prod parity Keep development, staging, and production as similar as possible
You might have seen issues, where something that was working and tested on a lower environment, suddenly starts showing some erroneous behavior in production. This can be due to some mismatch in terms of tools/ library versions. To avoid such a situation it is recommended to keep all environments as similar as possible.
XI. Logs Treat logs as event streams
Logs are the lifeline of any application and their importance becomes more with a distributed system (say there is an issue, you need to know where the problem is in a distributed system which might consist of tens of applications). But log handling should not be the responsibility of the code. All logs are streamed out to a specialized system meant to manage logs like Splunk or ELK.
XII. Admin processes Run admin/management tasks as one-off processes
There can be some one-time maintenance tasks like database migration or backup, report generation, a maintenance script, etc. The idea is to keep these tasks independent of the core application and handled separately.