In his post, Martin Fowler talks about Strangler Figs
They seed in the upper branches of a tree and gradually work their way down the tree until they root in the soil. Over many years they grow into fantastic and beautiful shapes, meanwhile strangling and killing the tree that was their host.
This gives a definition to a prevalent development pattern when you are working on moving an existing monolith application to a new microservices-based cloud-native application. You do not make the change in one go, but instead, start small, take a part or functionality from the application, move it to a newer cloud-native microservice, and then remove that piece from the existing application. Step by step the old application is completely replaced by a fresh cloud native microservice-based application.
There will be three phases to such a transition
Transform: Create a parallel application build in microservices, cloud-native design.
Coexist: Incrementally you will implement features and transfer traffic from older monolithic applications to newly built cloud-native applications.
Eliminate: Completely remove the older version and only maintain the new application.
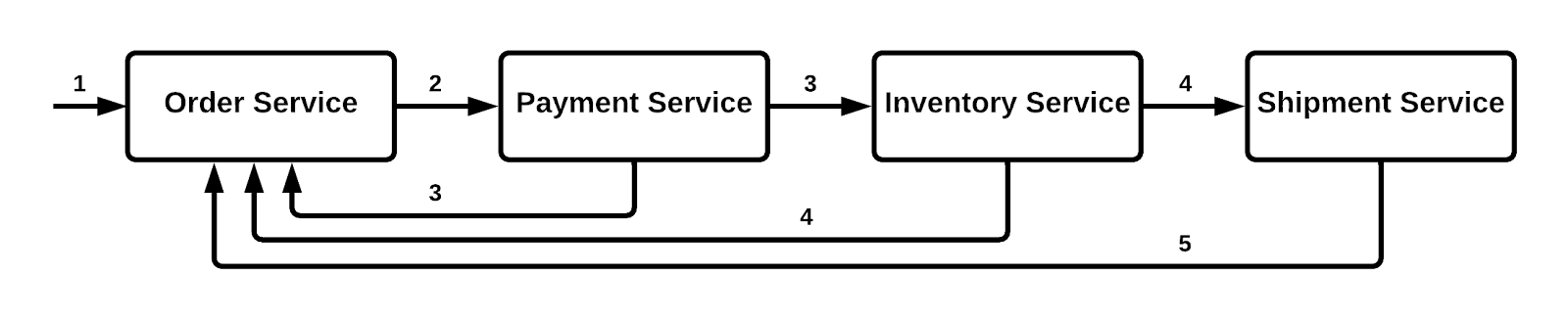
When developing cloud native applications using microservices, there might be time when you want to manage a transaction, where it is set of microservices working with each other to complete the process. For example, lets take a look at example below for placing an order in a e-commerce website.
The Saga design pattern is a way to manage data consistency across microservices in distributed transaction scenarios. A saga is a sequence of transactions that updates each service and publishes a message or event to trigger the next transaction step. If a step fails, the saga executes compensating transactions that counteract the preceding transactions.
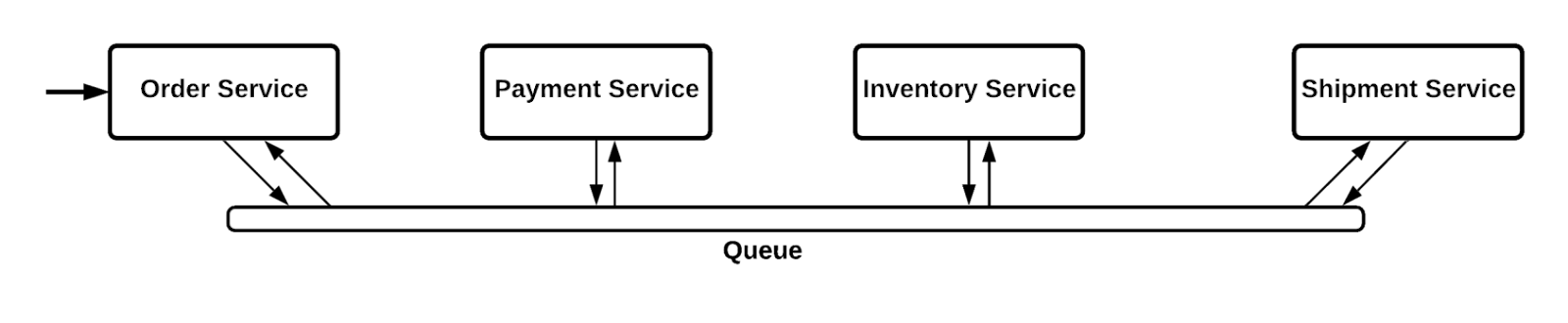
Choreography based SAGA: Event-driven communication across various services. Each service publishes events to the queue, which is listened to by the interested services. The listener services will perform actions based on the data received.
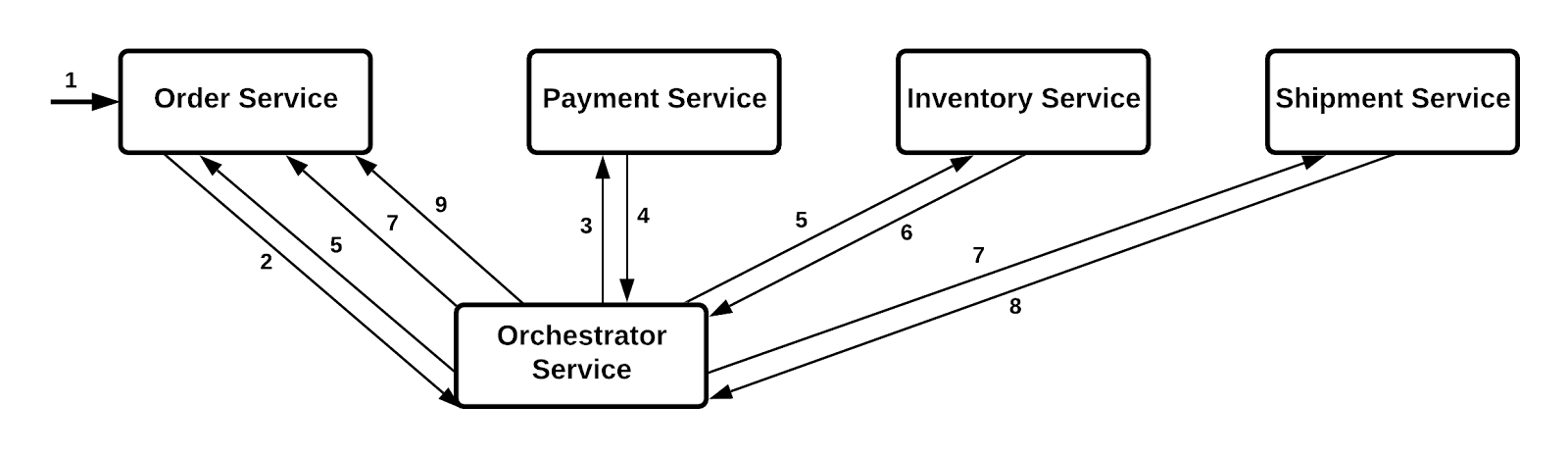
Orchestration based SAGA:
The central role in this type of implementation is played by an orchestrator. The orchestrator service takes control of the overall communication among various services.
Not planning to write yet another article on best practices for REST APIs as the topic is covered multiple times already. What better than Google’s reference document – https://cloud.google.com/apis/design/naming_convention
Here I would like to discuss some cases which are not straightforward. But before going there it makes sense to revise some basic concepts.
REST stands for Representational State Transfer. One can manage state of a resource.
The key abstraction of information in REST is a resource. Any information that we can name can be a resource. For example, a REST resource can be a document or image, a temporal service, a collection of other resources, or a non-virtual object (e.g., a person).
The state of the resource, at any particular time, is known as the resource representation.
The resource representations are consist of:
the data
the metadata describing the data
and the hypermedia links that can help the clients in transition to the next desired state.
When we say REST can help to manage resources (CRUD operations), it is done by following methods
POST for Create
GET for Read
PUT and Patch for update
DELETE for Delete
There are other methods like options and head, but we will focus on the core CRUD operations mentioned above.
To get started let’s take a simple use case, where we have a resource Employee
Generic URL format will look like /{baseurl}/{service or microservice}/{resource}
For example https://api.kamalmeet.com/employee-management/employees
GET list of the employees GET/employees
Get specific data GET/employees/{id}
Create a new object POST/employees
Update an employee object Patch or PUT /employees/{id}
Delete the object DELETE /employees/{id}
Now that was the easy part
Let us talk about some complex cases now, which are not straightforward to fit into REST naming conventions.
Fetch Related resources for the object
/employees/{id}/projects/
Controller verb for a special operation
/users/{id}/cart/checkout
Complex resources representation
only get specific orders (dashes are acceptable)
/users/{id}/pending-orders/
Fetch only specific columns
/employees/?fields={name, department, salary}
Complex searches (reports)
/search/?params={}
/reports/absentreport
Complex listing
/myorders
Above are some of the acceptable practices. Users can modify as per their needs.
Designing or architecting a system is a complex task. One needs to think of various aspects that can impact a system. At a high level, we bucket the requirements into two parts – Functional and Non-Functional. Functional requirements, in simple words, can be thought of as functionalities one needs to build. Non-functional requirements can be complex as they usually will not be called out explicitly and as an architect, you need to figure out after discussions with various stakeholders.
In this post, I would try to look at the system design for Netflix. Of course, it is a complex system and it is difficult to cover in one post, but I will try to touch upon important aspects.
Functional Requirements:
Account Management: Create Account/ Login/ Manage and Delete the Account
Subscription Management
Search
Watch a Video: View/ Download for offline viewing
Recommendations: User-based/ Generic/ Top trends/ Genre
Device Synchronization
Language Selection: Audio/ Video
Non-Functional Requirements:
Performance: Realtime streaming performance
Reliability
Availability
Scalability
Durability
Data needed:
number of users
daily active users
the average number of videos watched per day/ per user
Microservices-based architecture: Netflix is an early adapter of microservices and helped popularize the use of microservices. Microservices help Netflix manage its critical services by keeping them stateless, secured, scalable, available, and reliable.
CDN or Content Delivery Network: In the image above we see Open Connect, which is Netflix’s CDN. For any application which has consumers across multiple geographies, CDN is an important piece. This helps deliver content like images, videos, JavaScript, and other files from a location nearest to the user helping improve performance. In addition, Netflix provides Open Connect Appliances to ISPS free of cost, which helps ISPs save bandwidth and helps Netflix Cache content for better performance.
Transcoding: Any video getting uploaded to Netflix then gets converted to videos of various resolutions. The video gets uploaded to a queue from where it is taken up by transcoder workers who after converting the video upload them to AWS S3. When a user clicks on a video to be played, the best option is chosen based on the client and bandwidth.
API Gateway: ZUUL is the API gateway used by Netflix, which provides features for gateway like security, authentication, routing, decorating requests, Beta testing (based on routing), etc.
Resiliency: It is a resiliency library by Netflix. It handles scenarios like timeout handling, failing fast by rejecting requests when the thread pool is full, circuit breaker when the error rate is heavy, fallback to default response, etc.
Cache: Netflix uses EV cache to provide performance, reduced latency, better throughput, and reduced overall cost. EV cache is a custom implementation of Memcache, which is not dependent on RAM and can use SSD.
Database: Netflix uses MySQL for data that needs ACID properties, data like user data. Read replicas are used to improve query performances. Cassandra is used for NoSQL, to keep data like browsing and watching history. Older history data can be moved to the compressed cheaper data store.
Logs Management: All log data is sent to Chukwa through Kafka. You can view logs on the dashboard. Finally, logs can be sent to S3 for further retention and usage.
Search: Elastic Search is used for indexing and searching.
Recommendations: Spark is used for data analysis. it helps rank content based on user history as well as using data from users with similar tastes. For example, if two users have given similar ratings to a movie, their tastes might be similar. Also if a user watches comedy content mostly, the recommendation engine might suggest more comedy content.
Solving any problem requires one to analyze various available solutions and then look at factors like space complexity, time complexity, and ease of development.
Problem statement: Find the longest common prefix from N number of Strings.
Example: “kamal”, “kamalmeet”, “kamaljeet” should return “kamal”
Solution 1- Vertical Scanning
Approach: Start with the first element of each string and compare for equality. Continue till a point we do not find the same character.
Pseudo code:
-- for i=0 to n, of the length of the first (any) string
---- check if ith character is equal for all string
------ if not, return string from 0 to i-1 character
Code:
public String longestCommonPrefix(String[] strs) {
for (int index = 0; index < strs[0].length(); index++) {
char ch = strs[0].charAt(index);
for (String st : strs) {
// one of the strings has ended or char mismatch found
if (index >= st.length() || st.charAt(index) != ch) {
return strs[0].substring(0, index);
}
}
}
// if you reached here, first string is longest common prefix
return strs[0];
}
Time Complexity: O(S) for Worst case all strings are equal, and S is the sum of all string lengths
Space Complexity: O(1) no additional data structure
Solution 2 – Horizontal Scanning
Approach: Start by comparing the first two strings and find the longest common prefix. Use this as input and compare it with next string and so on.
Pseudo code:
-- longestprefix = str[0]
-- for strings in i=1 to N
---- longestprefix = findlongestprefix(longestprefix, str[i])
-- return longestprefix
Time Complexity: O(S)
Space complexity: O(1)
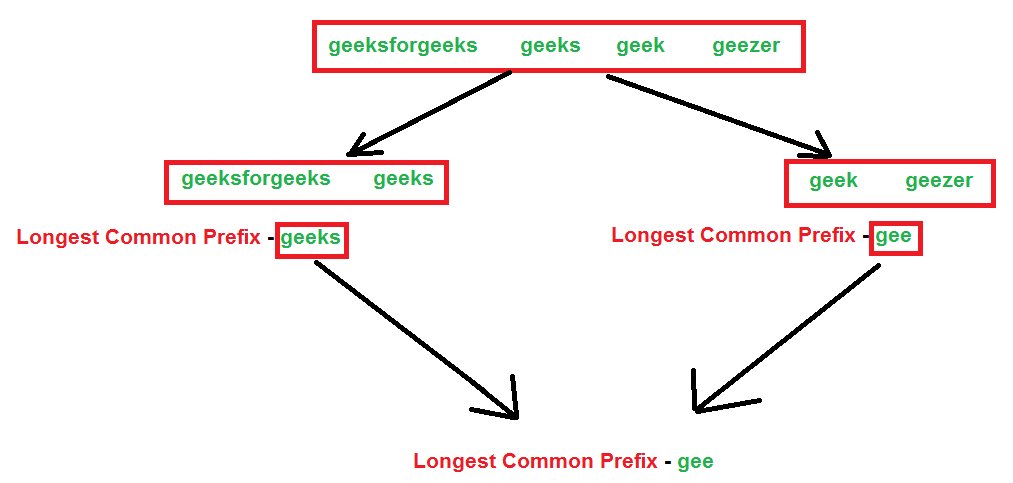
Solution 3- Divide and Conquer
Approach: Break down the array of strings into two equal parts, solve for the two subarrays, and find a solution for two results (repeat the process at each step).
Availability zones are created by using one or more datacenters. There’s a minimum of three zones within a single region. It’s possible that a large disaster could cause an outage big enough to affect even two datacenters. That’s why Azure also creates region pairs.
What is a region pair?
Each Azure region is always paired with another region within the same geography (such as US, Europe, or Asia) at least 300 miles away. This approach allows for the replication of resources (such as VM storage) across a geography that helps reduce the likelihood of interruptions because of events such as natural disasters, civil unrest, power outages, or physical network outages that affect both regions at once. If a region in a pair was affected by a natural disaster, for instance, services would automatically failover to the other region in its region pair.
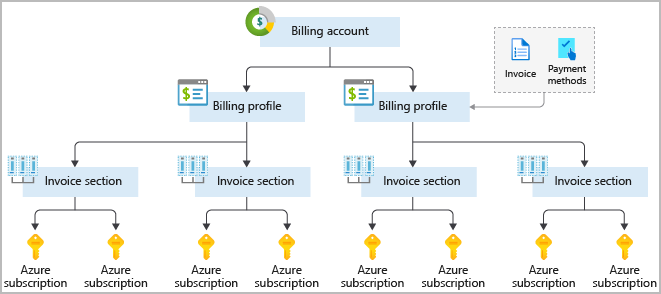
Customize billing to meet your needs
If you have multiple subscriptions, you can organize them into invoice sections. Each invoice section is a line item on the invoice that shows the charges incurred that month. For example, you might need a single invoice for your organization but want to organize charges by department, team, or project.
Depending on your needs, you can set up multiple invoices within the same billing account. To do this, create additional billing profiles. Each billing profile has its own monthly invoice and payment method.
The following diagram shows an overview of how billing is structured. If you’ve previously signed up for Azure or if your organization has an Enterprise Agreement, your billing might be set up differently.
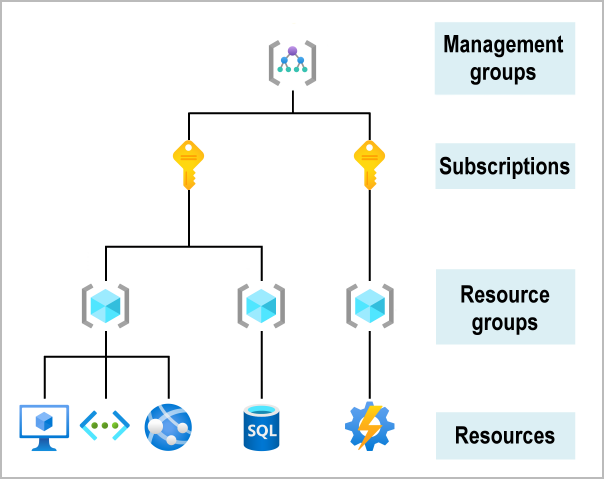
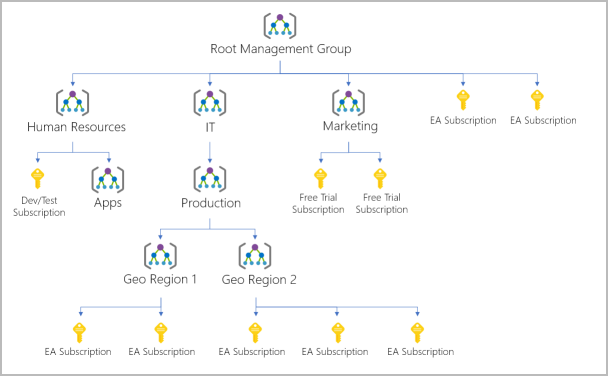
You can build a flexible structure of management groups and subscriptions to organize your resources into a hierarchy for unified policy and access management. The following diagram shows an example of creating a hierarchy for governance by using management groups.
You can create a hierarchy that applies a policy. For example, you could limit VM locations to the US West Region in a group called Production. This policy will inherit onto all the Enterprise Agreement subscriptions that are descendants of that management group and will apply to all VMs under those subscriptions. This security policy can’t be altered by the resource or subscription owner, which allows for improved governance.
In the previous post, I talked about the benefits of microservices. but the discussion will be incomplete without talking about some of the important challenges one should expect when going for microservices-based architecture.
Well, microservices provide a lot of benefits, but this definitely is not a silver bullet, and if not architected properly, the design can cause more pain than it will provide benefits. Here are some of the considerations one needs to keep in mind when designing an application with microservices.
Too few/ too many services: The first question one needs to deal with when going for microservices-based architecture is how to break the application into microservices. Too many microservices would mean you are unnecessarily complicating the system and too few would mean you are not getting the benefits of a microservice-based design.
Complex DevOps: Unlike a monolith application where you are deploying just a single application, not you are dealing with dozens of microservices. Each service needs its own compilation and deployment pipeline, which means independent management and tracking.
Monitoring: As multiple services are communicating with each other to make the application work, a single failure can impact the overall success. Hence it is important to monitor all services, which means a complex dashboarding, alerting, and monitoring system in place to keep a check on all pieces.
Multiple Tech Stacks: One of the advantages we get with microservices is the independence you get in choosing a tech stack for each piece, but too many tech stacks would mean difficult intra-team support and low expertise on technology.
Managing Data: Another challenge with microservice-based design is managing the data. As a rule of thumb, each microservice should manage its own data. But this can get tricky as sometimes microservices need to share data. If not managed properly one can run into a problem of duplicate sources of data or performance issues in fetching data from other services.
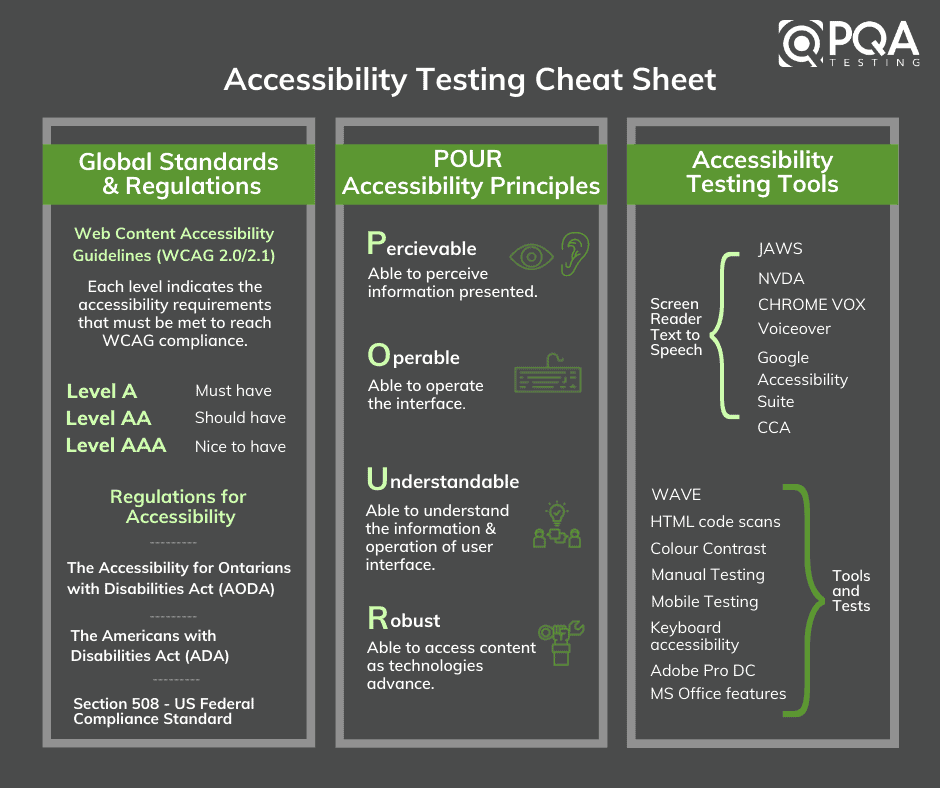
In the last post, I introduced the concept of accessibility, here I will discuss more on testing your application for accessibility. The good thing is that we have many tools that can help us with basic accessibility testing.
The first level of testing that you would like to do for accessibility would be for Keyboard navigation (does your application support tab/ arrow navigation) and Screen reader. All Operating systems come with inbuilt support for screen readers Windows has Narrator, Mac has VoiceOver, and there are readers like JAWS and NVDA.
Additionally, there are tools to help with accessibility testing, some of the common ones are following
Accessibility insights: Another tool that can help with testing and generating a detailed report for an application. Refer https://accessibilityinsights.io/. It gives not only details but also suggestions on fixes. Here is a sample report
As a software developer/ designer/ architect, when you think about software, there are many non-functional aspects of the software that you need to take care of. Accessibility is one such important non-functional aspect, which can get neglected if you are not paying attention.
Before getting into more details, let’s try to understand what accessibility is –
Accessibility enables people with disabilities to perceive, understand, navigate, interact with, and contribute to the web.
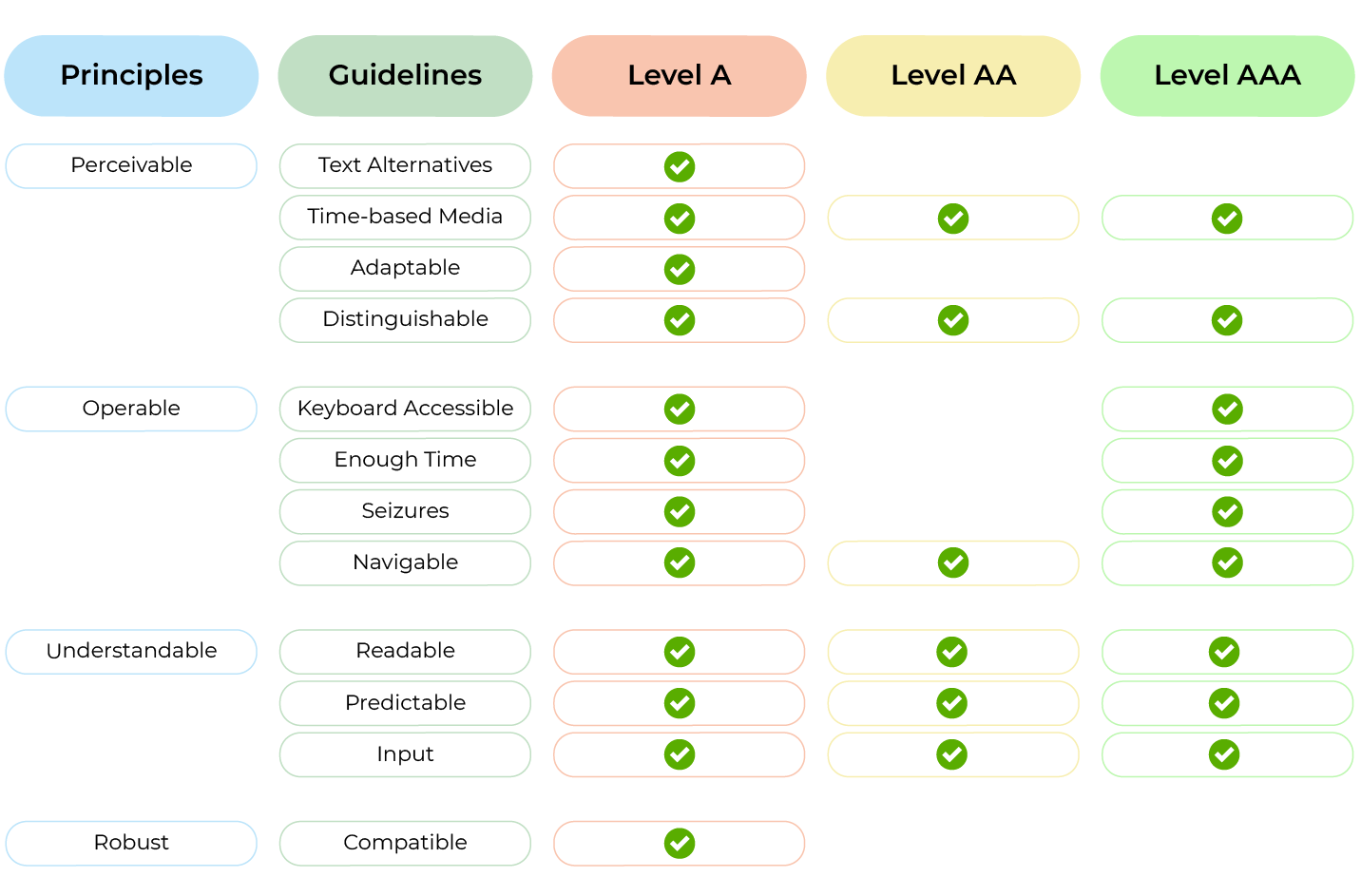
WCAG or Web Content Accessibility Guidelines, current version 2.1 gives us a detailed idea of areas one needs to consider when working on the accessibility of a website.
WAI-ARIA: Web Accessibility Initiative – Accessible Rich Internet Applications or WAI-ARIA is a specification developed by W3C in 2008.
WAI-ARIA, the Accessible Rich Internet Applications Suite, defines a way to make Web content and Web applications more accessible to people with disabilities. It especially helps with dynamic content and advanced user interface controls developed with HTML, JavaScript, and related technologies.
In the last post, I introduced the concept of microservices and why it is a default fit for Cloud Native Design. But an important question that should be asked is why microservice-based design has gained so much popularity in recent years. What all advantages microservices gives us over traditional application design?
Let us go over some advantages of microservices-based design here
Ease of Development: The very first thing visible in microservices-based architecture is that we have divided the application into smaller services. This also means we can organize our developers into smaller teams, focusing on one piece of deliverable, less code to understand, less code to the manager, and hence can be more agile.
Scalability: A monolith application is difficult to scale as you are looking at replicating the whole application. In the case of microservices, you can focus on pieces that are actually required to scale. For example, in an eCommerce system, a search microservice is getting a lot of requests and hence can be scaled independently of the rest of the application.
Polyglot programming: As we have divided applications into smaller pieces, we have flexibility in choosing tech stacks for different pieces as per our comfort. For example, if we know a certain Machine learning piece of application/ microservice can be developed easier in python, whereas the rest of my application is in Java, it is easy to make the choice.
Single Responsibility Services: As we have divided the application into smaller services, each service is now focusing on one responsibility only.
Testability: It is easier to test smaller pieces of applications than to test them as a whole. For example, in an e-commerce application, if a change is made in the search feature, testing can be focused on this area only.
Agile Development: As teams are dealing with smaller deployable now, it is easier and a good fit for Continuous Integration (CI) and Continuous Deployment (CD), hence helping achieve less time to market.
Stabler Applications: One advantage microservices architecture gives us is to categorize our microservices on basis of criticality. For example, in our e-commerce system, order placement and shopping cart features will be of higher criticality than say a recommendation service. This way we can focus on the availability, scalability, and maintenance of areas that can directly impact user experience.