Recently Amazon has conducted free online training to provide an introduction to core services provided by Amazon Web Services or AWS. Follow this link https://aws.amazon.com/events/awsome-day/awsome-day-online/ to get more details about the training. It was divided into 5 modules, where it talked at a high level about the major services provided by AWS. The training is very useful for anyone wanting to know more about AWS services or Cloud services in general.
Here is the summary of training:
What is the cloud?
All your infrastructure needs are provided to you off the shelf. You do not need to setup or maintain any infrastructure. You provision what you need and when you need it, and pay for only what you use.
The advantage you get is that you do not need to pre-configure infrastructure and pay for everything upfront. You need not predict the exact capacity you need. The cloud provides you with an option to pay only for what you use. You have easy options to scale up or down based on your needs.
How you manage the infrastructure?
On-Premise: When you maintain the whole infrastructure on your premises.
Online Cloud or Cloud: You do not maintain any infrastructure and everything is owned by the cloud service providers.
Hybrid: A mix of on-premise and online cloud.
Regions, Availability Zones, Data centers, and Edge location
Regions are the first thing you will need to choose when procuring a resource, mostly it is a geographic location like Singapore, US East, US west, etc. Each region has 2 or more availability zones (AZs). The availability zone has one or more data centers. Edge locations are customer-facing locations that can be set as endpoints for CDNs (Content Delivery Network).
An understanding of Regions and AZs is important to help us guide with Data governance legal requirements and proximity to customers (for better performance). Also, not all the services are available in all the regions, plus the cost might vary sometimes.
Amazon EC2: Virtual machines are the heart of any cloud system. Amazon provides EC2 or Elastic Cloud Compute to get compute resources. It has many configurations to choose from based on your needs.
Amazon EBS or Elastic Block Store: You can think of it as hard drives for your EC2. It is available in SSD and HDD types.
Amazon S3 or Simple Storage Service: S3 stores data in the form of objects. It gives 11 9’s or 99.999999999% durability. It is used for backup and storage, application hosting, media hosting and so on. You can secure and control access to your buckets using access policies. Also, you can turn on versioning to manage the version of objects/files. Additionally, you can also set up your bucket as a static website.
Amazon S3 glacier: This is low-cost storage for long term backup.
Amazon VPC or Virtual Private Cloud: You can manage your resources in Virtual networks, which gives you a way to manage access to the resources in the virtual networks based on security group rules.
Amazon Cloudwatch: Cloudwatch is a monitoring service. It gives different forms of usage metrics (CPU/ Network usage etc). One can add alarms and triggers based on events like CPU usage above a certain limit.
EC2 Autoscaling: Autoscaling allows us to add machines when traffic is raised and reduce machines when traffic is low. We can add or reduce EC2 instances based on events like CPU usage percentage.
Elastic Load balancing: Elastic Load Balancing is a highly available managed load balancing service. It provides Application Load balancer, network load balancer, and classic load balancer options. The application load balancer is layer 7 (application layer) load balancer which can be used based on request formats whereas Network load balancer works on layer 4 (network layer).
Amazon RDS or Relational Database service: supports Postgres, MariaDB, Oracle, MySQL, MS-SQL, Amazon Aurora. Aurora is a high-performance database option by AWS that supports MySQL and Postgres and is faster than normal databases as it is built in a manner to take advantage of cloud scaling mechanism.
Amazon DynamoDB: Dynamo DB provides various NoSql database options, which is built for low latency.
AWS Cloud formation: Clout formation gives us Infrastructure as code. You can code your templates which will then be used to deploy resources on AWS.
AWS Direct Connect: Direct Connect helps connect your on-premise infrastructure to AWS. You can bypass the internet and directly connect to AWS with help of Vendors that support direct connect.
Amazon Route 53: Route 53 is the DNS service where you can register and manage your domains.
AWS Lambda: AWS lambda provides an option to deploy your code in the form of functions directly on the cloud. You can focus on your code without worrying about the infrastructure on which it will run and scale.
Amazon on SNS: Simple Notification Service (SNS) is a fully managed pub-sub messaging service for distributed or serverless applications.
Amazon Cloud front: A fast, reliable content delivery network. A customer requesting from India will hit the nearest CDN and get the data delivered, hence much faster than accessing from the actual source which may be in the U.S. IT is a lazy loading content system. Therefore, for the first time, it will be getting data from sources but subsequent requests will get locally cached data on CDN.
Amazon Elastic Cache: Fully managed Redis or Memcached-compatible in-memory data store.
AWS Identity and Access Management (IAM): Manage users, group and roles. Users can be created and added as part of the groups. Groups and Users will be given roles through which they access resources. Roles can also be provided to applications and services like AWS Lambda so that they can access other resources directly.
Amazon Inspector: Does an analysis of your resources and provides a report for vulnerabilities and best practices.
AWS Sheild: It is provided out of the box in free and paid versions and help us protect applications from DDOS (Distributed Denial of service) attack.
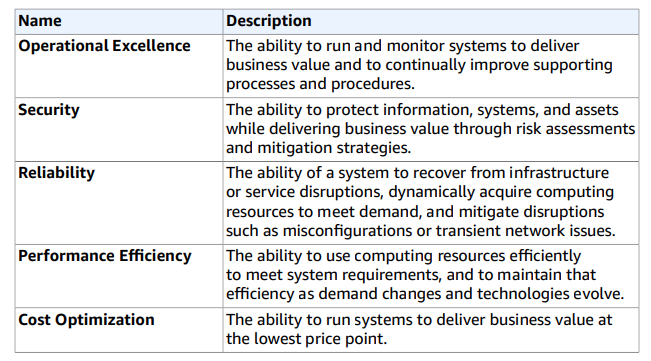
5 pillars of a good cloud architecture
Amazon recommends understanding 5 pillars of a good cloud architecture – https://d1.awsstatic.com/whitepapers/architecture/AWS_Well-Architected_Framework.pdf