When one starts a project, one question that needs to be answered immediately is how to manage the code? The branching strategy needs to be finalized, in the agile world, we want to make sure code gets merged and deployed asap. Continuous Integration and Continuous delivery want us to make sure our code is always in a state that is ready to be deployed on production.
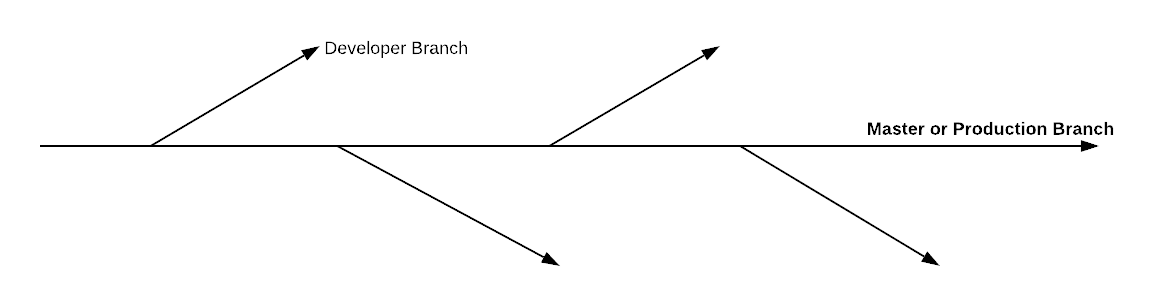
There are two most common branching strategies which are used in Industry. I have written about these in my book on microservices. Here is an overview.
Feature-Based Branching
The idea is to separate branches for each feature. The feature gets merged back to the production branch once it is implemented and tested completely. An important advantage this kind of approach gives us is that at any point in time there is no unused code in the production branch.
Single Development Branch
In this approach, we maintain a single branch in which we keep on merging even if the feature is incomplete. We need to make sure the half-built feature code is behind some kind of flag mechanism so that it does not get executed unless the feature is complete.
HTTP/2 has become a first-class citizen in the past couple of years where development teams have started realizing its true potential. Some of the core features of HTTP/2 are
Data compression of HTTP headers
Server Push
Multiplexing multiple requests over a single TCP connection
Some days back I wrote about SOAP vs REST. It will not be a stretch to say that with the popularity of REST, SOAP had a very limited business usage. REST seems like a natural extension of HTTP based communication where we used HTTP verbs like GET, POST, PUT, DELETE patch to update a resource state. REST as the name Representational State Transfer suggests an intuitive set of APIs
GET /employees – One can conclude that this will return a list of employees GET /employees/1 – returns employee with ID 1
Though REST is good, at times it feels like a restriction, say for a simple use case where I want to tell the API that for a given employee just give me a name. To handle these cases, GraphQL has gained a lot of popularity. GraphQL is a query language or way to get data from APIs.
GraphQL is a specification and not an implementation in itself. So you will find multiple client and server implementations available to choose from. For example, Facebook providers with Relay library. Another popular implementation is Apollo. In a typical REST APIs availability, you have a separate endpoint for each call. In the case of GraphQL, you have a single endpoint where you send your query.
gRPC is an open-source Remote Procedure Call system initially developed by Google. It uses HTTP/2 for transport, and protocol buffers as its underlying message interchange format. Remote procedure calls give users a feel of making calls to remote code as if they are available locally. The streaming approach behind the scenes makes sure the calling method receives a response as soon as it is ready on the remote machine.
A comparative view of the three approaches i.e REST vs GraphQL vs gRPC
Sometime back, I talked about HTTPS, and discussed how SSL or Secured Socket Layer can help us establish a secured connection between client and server. TLS or Transport Layer Security can be thought of as an updated version of SSL protocol.
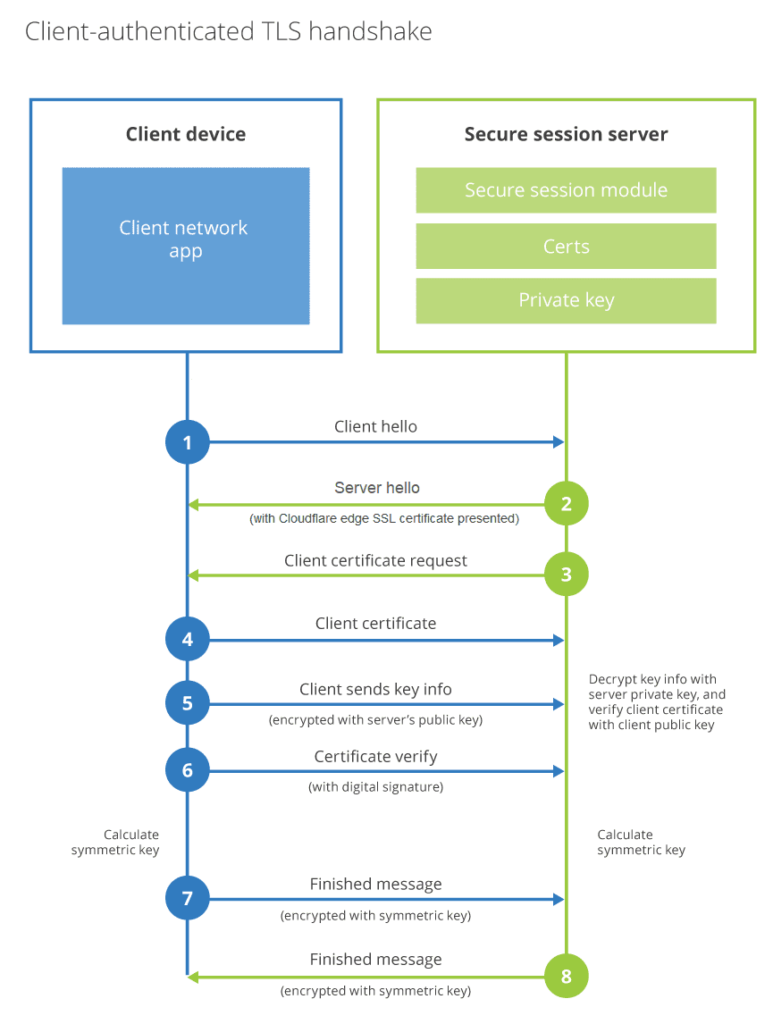
The image below shows the standard handshake process in TLS based communication. When a client tries to communicate with the server, the server sends back its certificate to the client along with its public key. Client after authenticating the server certificate sends the symmetric key encrypted by the public key shared by the server earlier. The server decrypts the key and finally, their communication is done using the symmetric key.
In the case mentioned above, we can see how the client, mostly the browser, validates the server certificate to trust it. An extension to the above communication style is mutual TLS or mTLS. As the name suggests, we are referring to a scenario where both server and client need to trust each other, mostly in this case client is another service or IOT based device. In this case, both the client and server will share their certificates and build mutual trust by authenticating the certificates.
Off late I have been working on and exploring some API proxy tools. I have seen the terms API proxy and API gateway being used interchangeably most of the time, and probably somewhere both try to solve similar problems, with a slight change.
When we talk about API proxy, we are talking about reverse proxy functionality where we can expose our existing APIs to the outside world through a proxy server. So the user applications are not directly talking to your APIs but interacting through the proxy. The idea here is simple, that you need not let everyone know internal details about how and where your servers are deployed. API proxy can also work as a load balancer for API deployed on multiple servers. It can provide additional features like monitoring, quota implementation, rate limiting for your APIs.
An API gateway does all that and provides add-on features like orchestration, for example, when the client hits “/products” API, the gateway might talk to multiple services and collaborate the data before sending back. Additionally, it can provide Mediation like converting request or response formats. It can also help expose a SOAP service as a set of REST endpoints and vice versa. It can provide sophisticated features like handling DDOS attacks.
There is no hard boundary line between API Proxy and API Gateway, and we will find the terms being used interchangeably. Features too, at a certain level, are overlapping. So at the end of the day just look for the tool that fulfils your requirements.
With the popularity of microservices-based design, we are ending up with tens and hundreds of APIs being created for our applications. Apigee is a platform for developing and managing APIs. It provides a proxy layer for our backend APIs. We can rely on this proxy layer to provide us with a lot of features like security, rate limiting, quotas implementation, analytics, monitoring, and so on.
The core features provided by Apigee are
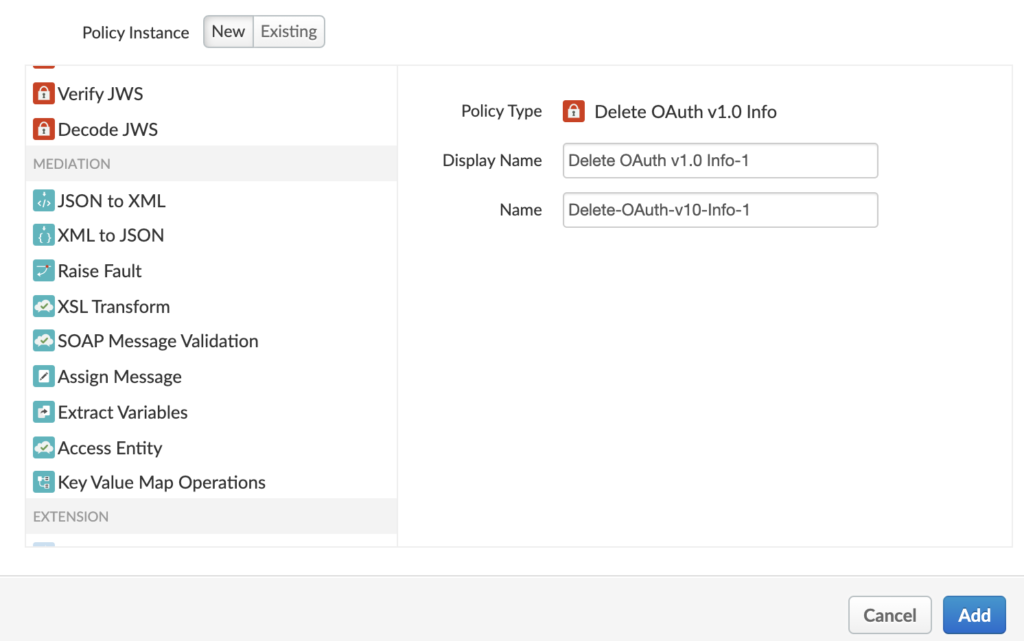
Design: One can create APIs, and configure or code policies as steps in API flows. Policies can help implement features like rate limiting, quota implementation, payload transformation, and so on.
Security: One can enforce security best practices and governance policies. Implement features like authentication, encryption, SSL offloading, etc at the proxy layer.
Publish: We can provide reference documentation and manage the audience for the API from the portal.
Analyze: Drill down usage data, investigate the spikes and trace calls in real time.
Monitor: Ensure API availability and provide a seamless experience to the APIs.
Hands on example
Getting started with Apigee is easy, go to https://apigee.com and create a free 60-day evaluation account for testing. Once logged in, choose the API proxies option to get selected.
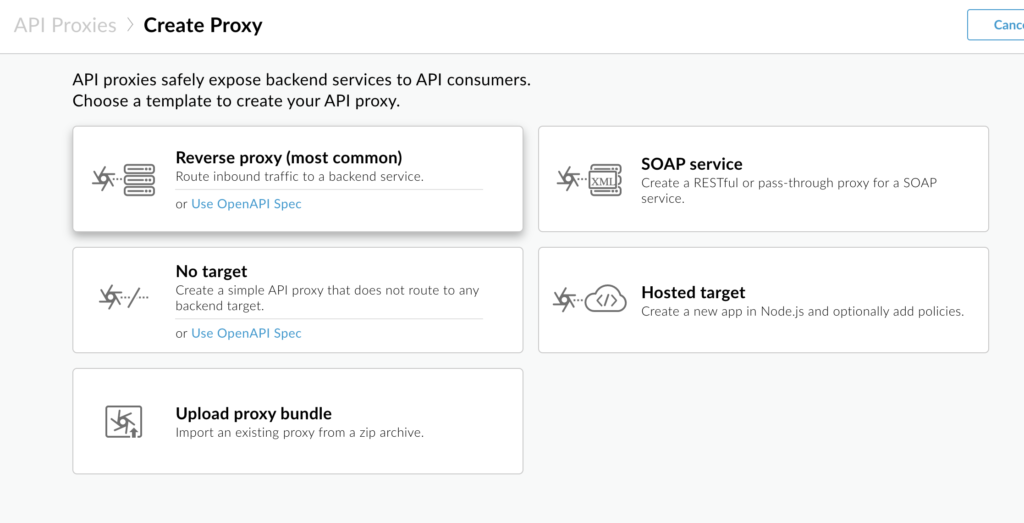
Create a new proxy, and we will select reverse proxy to start with.
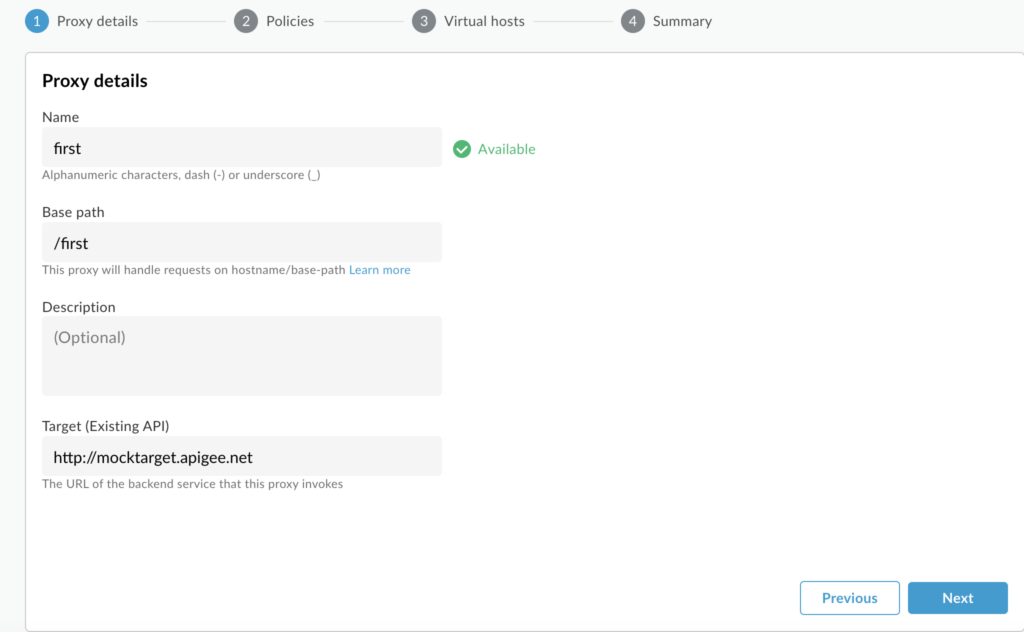
To start with, we will use the sample API provided by apigee- http://mocktarget.apigee.net (just prints string “Hello Guest”), and provide name, base path, and some description. You can see we have several other options like SOAP service, which is very useful if you have an existing SOAP service and want to expose it as REST services. Also, there is a No Target option which is helpful when we are creating Mock APIs to test our client applications. But as mentioned, for now, we are creating a reverse proxy for this example.
For the first iteration, we will not add any policy and leave all other options as default (no policy selected).
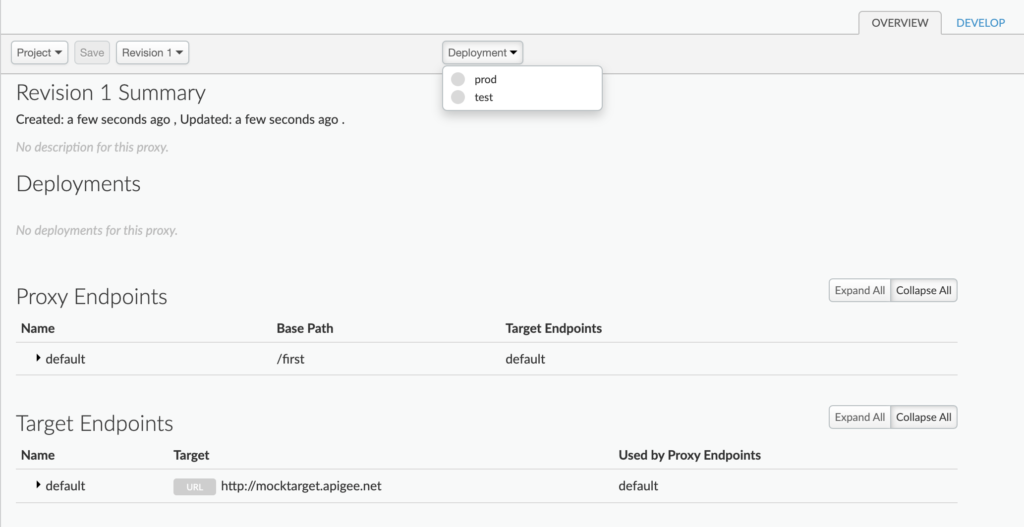
Once created, we will deploy the API to the test environment. For a free evaluation version, we are provided two environments only, test and prod.
After successful deployment, a proxy URL will be provided by apigee, something like https://kamalmeet-eval-test.apigee.net/first, which we can hit and get the output (Hello Guest). We can see that we are hitting proxy URL which in turn hits the actual URL, in this case, http://mocktarget.apigee.net/.
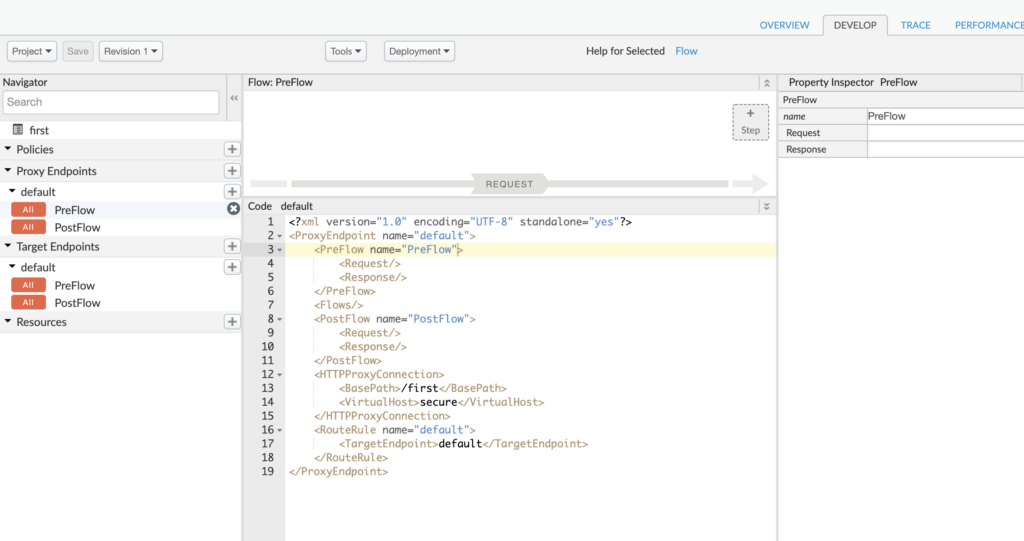
Go get an understanding of what is happening behind the scenes, we will look into the “Develop” tab.
We can see two sets of endpoint settings, a proxy endpoint, and a target endpoint. The proxy endpoint is the one exposed to the calling service. The target endpoint is the one that is communicating with the provider service.
Currently, we have not done much with the endpoints so we see very basic XML settings. On the proxy side, all we see is connection /first and the fact that we are exposing a secured URL. Similarly, on the target side, all we have is the target URL.
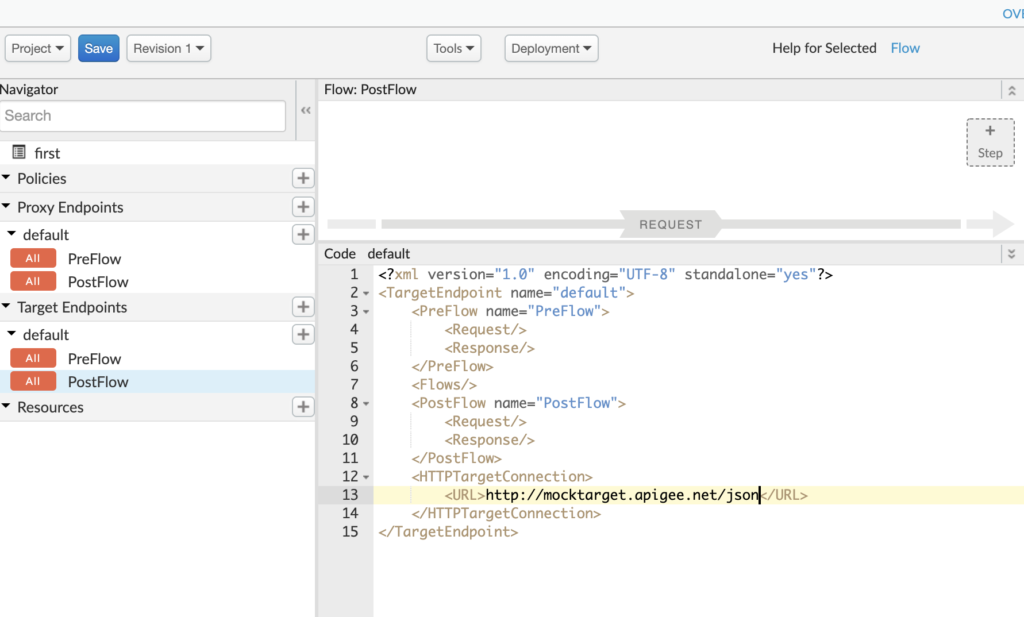
To make the API more meaningful, let’s modify the target endpoint to https://mocktarget.apigee.net/json, which returns a sample JSON like
We can update the same Proxy that we created earlier or create a new one. To update the existing one, just go to the develop tab and update the target endpoint URL.
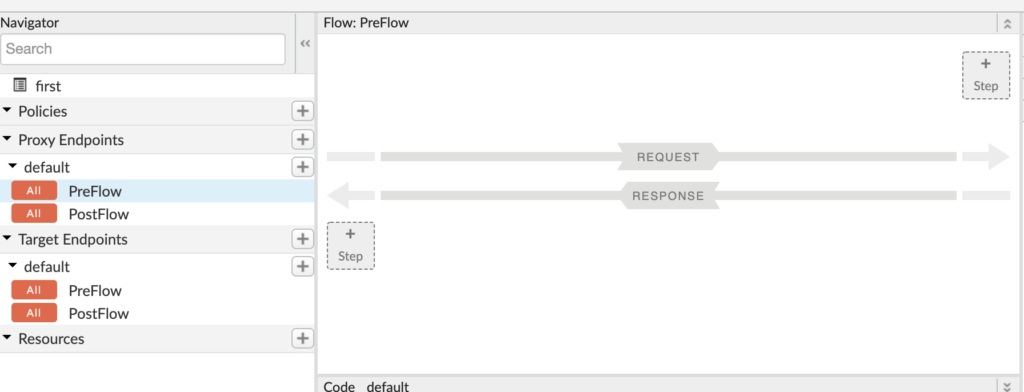
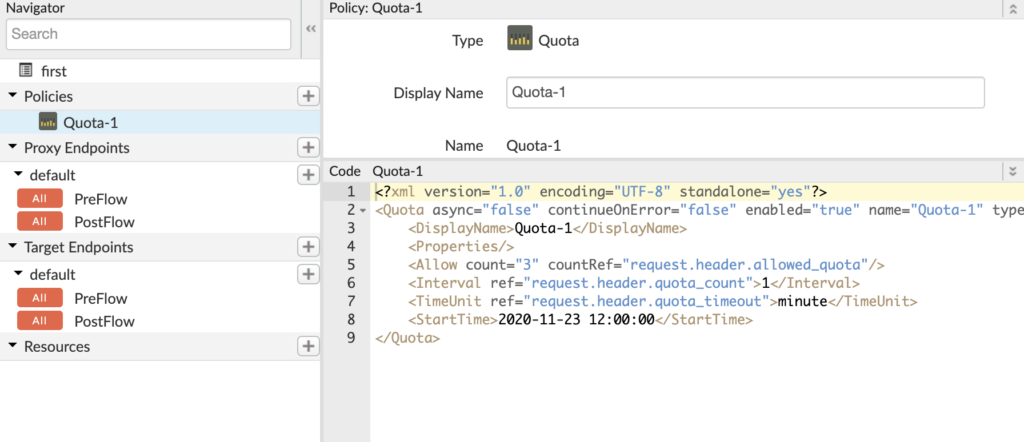
When you click on save, it will deploy automatically (else you can undeploy and deploy). Once done, you will see the existing proxy URL that we created now returns the JSON response https://kamalmeet-eval-test.apigee.net/first. So far we have not added any policy to our APIs. Well, that is easy, in the same develop tab, just above the XML definitions we see a flow diagram.
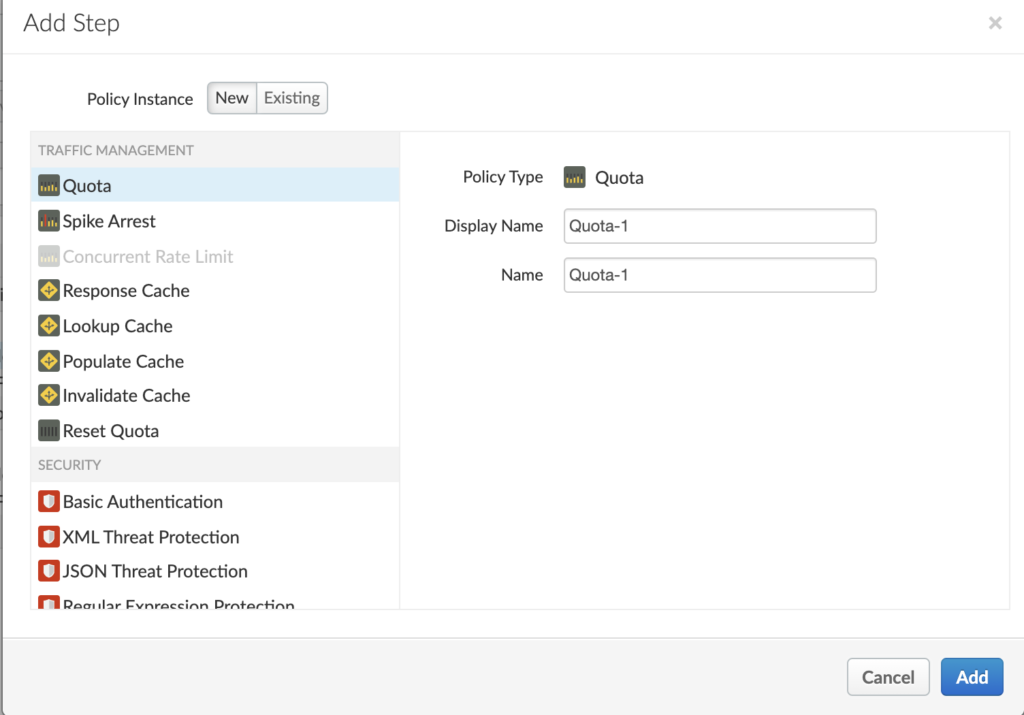
We can add a step to request flow or response flow. Let’s add a policy to request flow by clicking on the +Step button. To start, let’s add a quota policy.
By default, the quota policy gives settings for 2000 requests per month. For sake of this test, let’s modify it to 3 calls per minute.
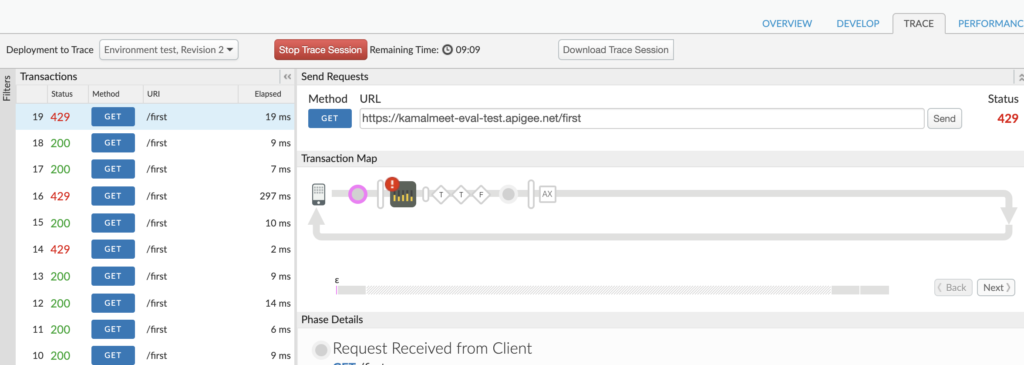
To test the quota implementation, we can go to the trace tab and hit the URL multiple times. We can see response code 429 (too many requests), caused by the quota limit.
We have implemented the quota policy, which can be very useful to stop a bot attack on our API. Similarly, Apigee provides us with a set of policies categorized under traffic management, security, and mediation. For traffic management, we have a quota, spike arrest, caching, etc. For Security, we have policies like Basic Auth, JSON threat protection, XML threat protection, OAuth, and so on.
For mediation, we have policy likes, JSON to XML, XML to JSON, XSL transformation, etc.
In the example we created, we added a policy to the incoming request, similarly, we can add a policy to response, for example, if we apply JSON to XML policy to the response, we will start receiving XML response instead of JSON.
Often you need to make a decision how your services will accept the message payload from calling services or clients. The two popular ways to implement messaging between services is SOAP and REST.
SOAP or Simple Object Access Protocol relies on a very specific message format to pass on the information. It uses XML based messages, and a message usually contains an envelop, headers, body and fault part. It provides built in error handling, when a request has an error, response would give proper error details.
A discussion about SOAP is incomplete without referring to WSDL. Web Service Description Language is an XML based document which gives details regarding the WebService. How many services it provides, how to invoke the service, what kind of request and response is expected, and so on. WSDL is shared with calling or client services, which can use it to understand the provider service structure. Many languages have automated tools or libraries to generate client code automatically using the WSDL.
WSDL 1.1 Term
WSDL 2.0 Term
Description
Service
Service
Contains a set of system functions that have been exposed to the Web-based protocols.
Port
Endpoint
Defines the address or connection point to a Web service. It is typically represented by a simple HTTP URL string.
Binding
Binding
Specifies the interface and defines the SOAP binding style (RPC/Document) and transport (SOAP Protocol). The binding section also defines the operations.
PortType
Interface
Defines a Web service, the operations that can be performed, and the messages that are used to perform the operation.
Operation
Operation
Defines the SOAP actions and the way the message is encoded, for example, “literal.” An operation is like a method or function call in a traditional programming language.
Message
n/a
Typically, a message corresponds to an operation. The message contains the information needed to perform the operation. Each message is made up of one or more logical parts. Each part is associated with a message-typing attribute. The message name attribute provides a unique name among all messages. The part name attribute provides a unique name among all the parts of the enclosing message. Parts are a description of the logical content of a message. In RPC binding, a binding may reference the name of a part in order to specify binding-specific information about the part. A part may represent a parameter in the message; the bindings define the actual meaning of the part. Messages were removed in WSDL 2.0, in which XML schema types for defining bodies of inputs, outputs and faults are referred to simply and directly.
Types
Types
Describes the data. The XML Schema language (also known as XSD) is used (inline or referenced) for this purpose.
REST or Representational State Transfer is an architectural style rather than a protocol which lets one use HTTP verbs to communicate among services. It helps making the communication easier as there is no restriction in format of data being sent. Also it is often easier to implement and lightweight as no need for XML parsing on client and provider side.
HTTP method
Description
GET
Get a representation of the target resource’s state.
POST
Let the target resource process the representation enclosed in the request.
PUT
Set the target resource’s state to the state defined by the representation enclosed in the request.
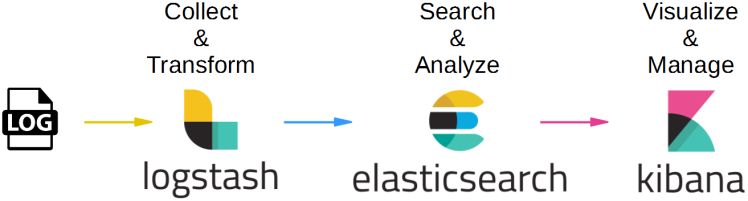
In the last three posts, I had talked about three popular off the shelf monitoring tools by cloud service providers, i.e. AWS CloudWatch, Azure Application Insights, and Azure Monitor. A discussion about monitoring cloud-native applications and microservices is incomplete without discussing ELK stack. ELK stack provides end to end functionality from capturing logs, indexing them in a useful manner, and finally visualizing them in a form that makes sense. Three core components that make the ELK stack are Elastic Search, Logstash, and Kibana.
As the image above shows, three tools forming ELK stack work together, where Logstash is responsible for the collection and transformation of logs, ElasticSearch indexes and makes logs searchable, and finally Kiabana helps them visualize in forms of reports which are easy o make sense of.
Let’s take a look at these three components.
ElasticSearch: is a popular search engine implementer. It indexes data and helps in implementing quick searches. It is based on Apache Lucene and provides REST APIs for accessing data. It is highly scalable and reliable, implemented on the No-SQL database.
Logstash: provides connectors for various input sources and platforms, helping in the collection of logs data from different sources. It can collect, parse, and manage a variety of structured and unstructured data.
Kibana: is basically a visualization tool, provides various user-friendly visual options for reporting like graphs, bars, tables, etc. One can create and share dashboards for an easy understanding of data in form of visual reports.