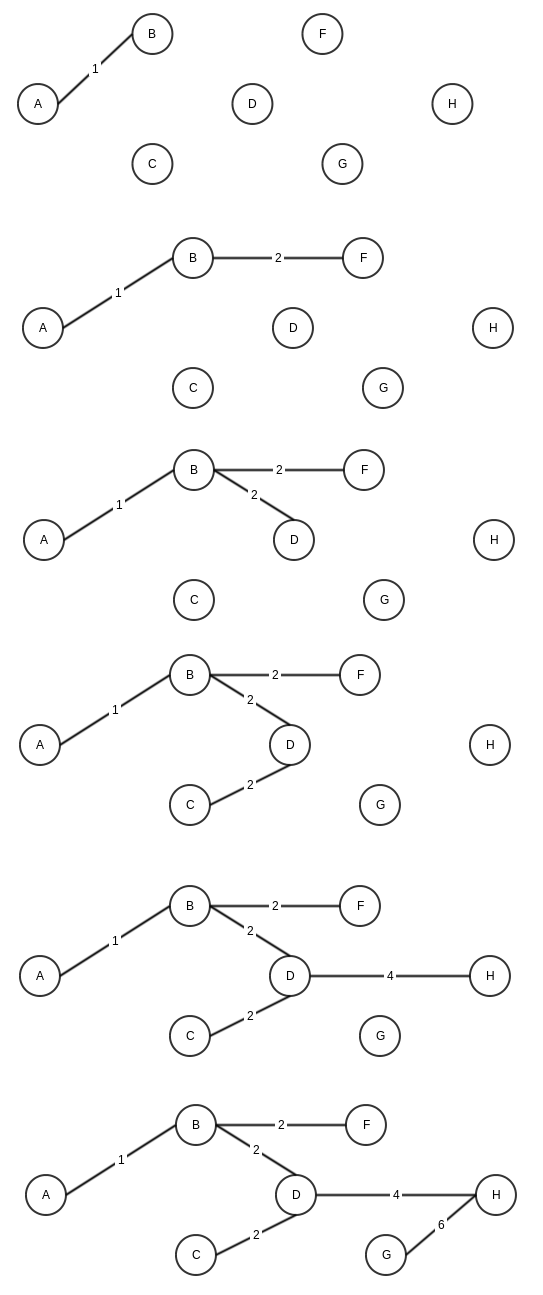
Sometime back I wrote about Binary Search Tree (BST) and AVL tree. AVL tree helps us maintain search at an O(log N) complexity. The price we have to pay, is to maintain balance of tree with every insertion or deletion in tree.
Red black tree, is another balanced BST, but not as strictly balanced as AVL. A red black tree, has following properties.
1. Each node is marked either red or black.
2. Root is always black (does not impact actually- read on)
3. Each leaf node is null and black (It is optional to show leafs, but good for initial understanding).
4. Imp- No 2 red nodes can be directly connected, or no red node can have a red parent or child.
5. Imp- A path from root to (any) leaf will always have same number of black nodes.
Property 4 & 5 makes sure we always end up in a balanced BST.
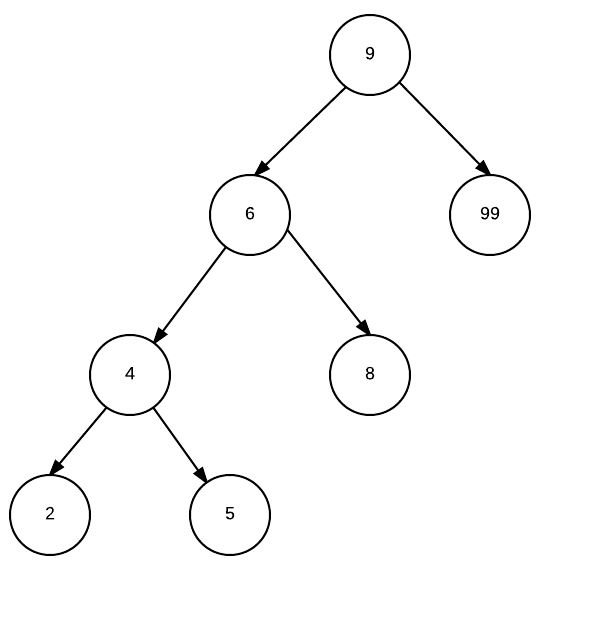
here is an example red black tree. (image from wikipedia)

Here is a good illustration of how red black tree works – http://www.cs.usfca.edu/~galles/visualization/RedBlack.html
As red black tree gives a bit flexibility over AVL in tree balancing, insert operation is faster than AVL with less number of tree rotations. The insert speed comes at a cost of a tad slower searching, though it is still O(log N), the levels can be 1 or 2 more than AVL as tree is not strictly balanced.
Further readings
http://www.geeksforgeeks.org/red-black-tree-set-1-introduction-2/
https://en.wikipedia.org/wiki/Red%E2%80%93black_tree
https://www.cs.auckland.ac.nz/software/AlgAnim/red_black.html
http://stackoverflow.com/questions/1589556/when-to-choose-rb-tree-b-tree-or-avl-tree
http://stackoverflow.com/questions/13852870/red-black-tree-over-avl-tree