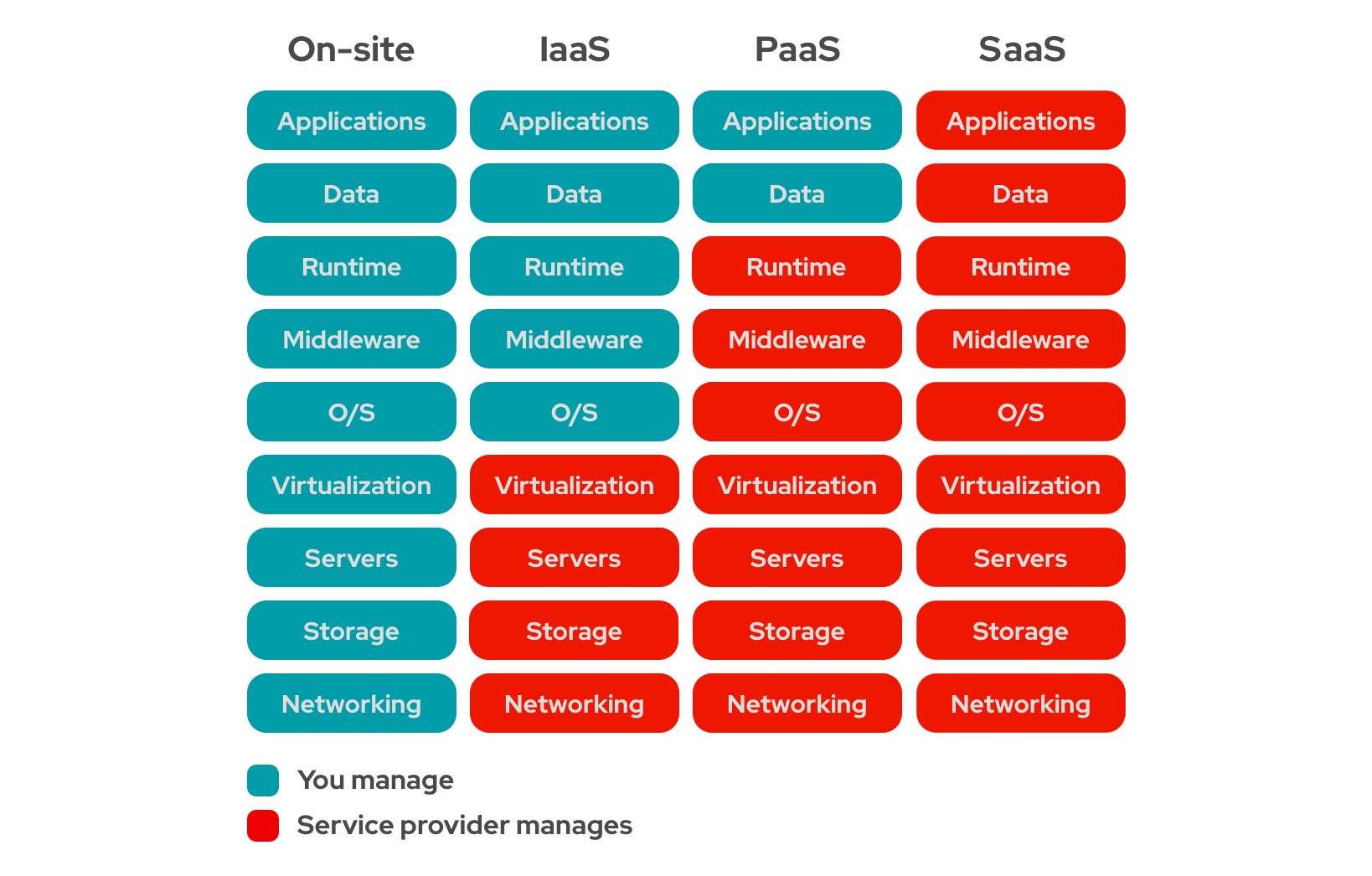
I cannot tell you whether the cloud has popularized microservice-based design or is it vice versa, but both go hand in hand. To understand this, let us take a quick trip to the history of the most popular application designs in past few years.
Monolithic design: If you are in the software Industry for more than a decade, you know that there was a time when the whole application was written as one single deployable unit. This does not sound bad if the application itself is small, but as the size of the application grows, it becomes difficult to manage, test, and enhance.
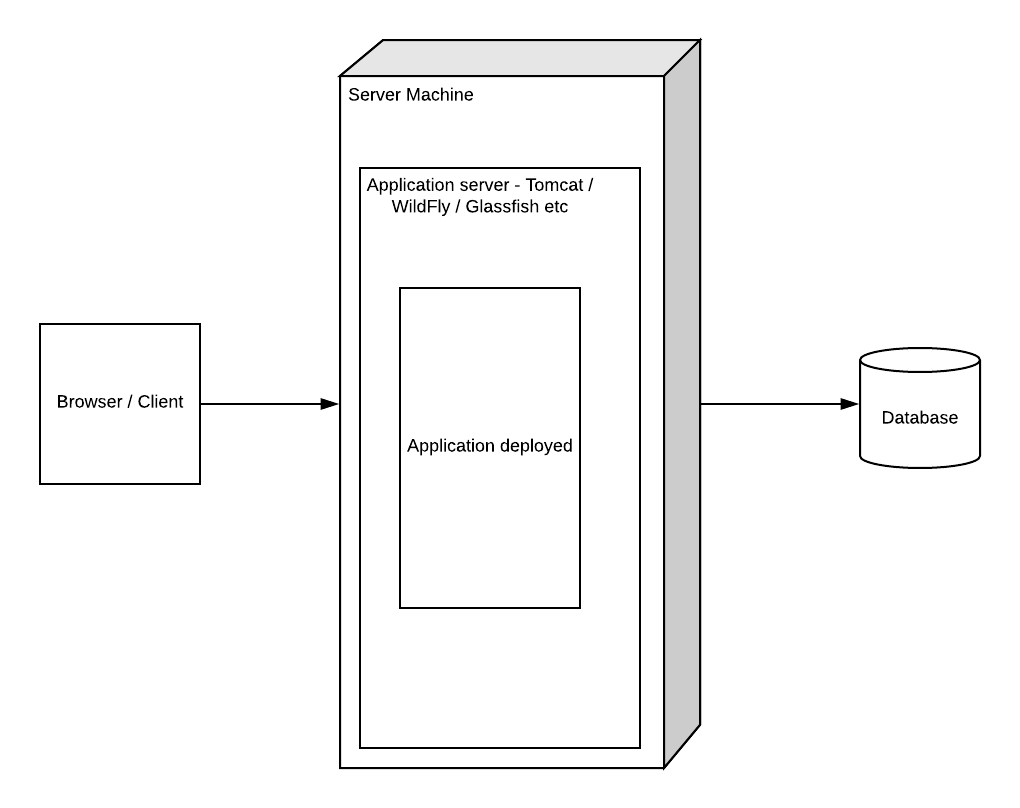
Some of the important challenges with monolith design were – difficulty to update, even a small change needing complete testing and deployment, being stuck with a tech stack, and difficult scaling.
Service-Oriented Architecture: The challenges in Monolithic design paved the way for an architecture where code was distributed in terms of services, hence called Service-Oriented Architecture or SOA. For example, in an e-commerce platform, we will have services for product management, inventory management, shipping management, and so on. This design helped in better organizing the code, but the final application was still compiled into one deployable and deployed to a single application server. Because of this limitation, this inherited most of the challenges from Monolith design.
Microservices: Though SOA inherited challenges from the Monolith era, one important change it brought was to the mindset of the developers and architects. We started looking at the application not as a single piece but as a set of features coming together to solve a common purpose. With the cloud, Infrastructure related limitations were reduced to a great extent, hence giving us the freedom to further divide the application not only at design time but also at run time.
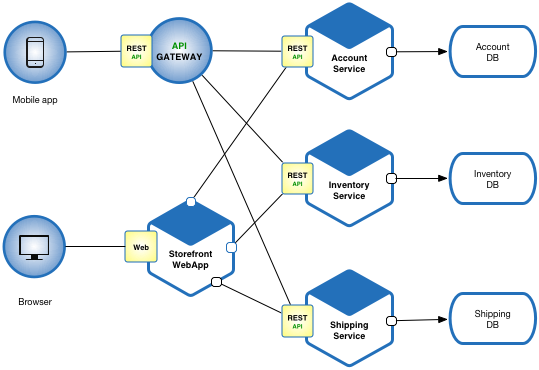
A major change that has come with Microservices is that you are breaking your application into a smaller set of services (hence the term microservice), which can solve one piece of the problem independently. This microservice is designed, developed, tested, deployed, and maintained independently. This also solves most of the problems we faced in Monolith design, because now you can scale, manage, develop (hence use independent tech stacks), and test these microservices independently.