If you will look around you will find many sets of best practices available for creating web applications, microservices, cloud-native applications, and so on. Developers and teams generally tend to share their learnings while they have gone through the process of application development. One needs to understand, learn and figure out what one can use in our application development process.
One such list of best practices, which is very popular among developers and architects is “The twelve-factor app”. https://12factor.net/
There are definitely some interesting points in this, that we should understand and use.
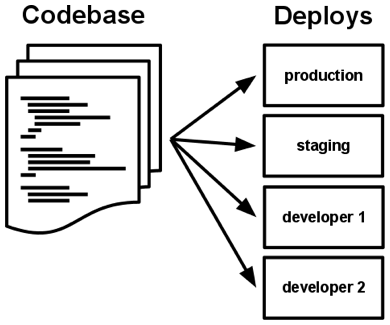
I. Codebase
One codebase tracked in revision control, many deploys
Always track your application via the version control system
Each microservice should be in its own repository
One repository serves multiple deployments e.g. dev, stage, and prod
II. Dependencies
Explicitly declare and isolate dependencies
An application has different dependencies to make it work, these can be libraries (jar files), third-party services, databases, etc. You must have seen scenarios where the application is behaving differently on two machines and eventually it is figured out the problem was a different version of a library on the machines.
The idea here is to call out all dependencies explicitly (dependency managers like maven, property files for any third-party dependencies), and isolate them from the main code, so that any developer now can start with a bare minimum setup (say install only Java on the machine) and get started (all dependencies are managed and downloaded separately).
III. Config
Store config in the environment
Your application has environment-specific configurations (dev, stage, and prod) like database, caching config, etc.
Keeping configurations with code can have multiple issues
- you need to update the code and deploy for any configuration changes
- As the access to code will be with most of the developers, it will be difficult to keep control of who can make changes and prone to human errors
To avoid these we will need to keep configurations within the environment.
IV. Backing services
Treat backing services as attached resources
Backing services can be databases, storage, message queues, etc.
Treating them as resources means that we can replace them easily for example moving from rabitMQ to ActiveMQ
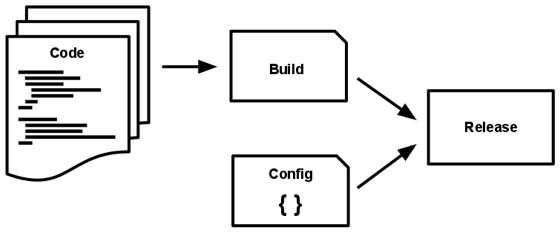
V. Build, release, run
Strictly separate build and run stages
Clearly define and separate stages
Build: Results in deployable like war, jar, or ear file that can be deployed to an environment
Release: Club build deliverables with environment-specific configuration to create a release
Run: A Release is run, e.g. a docker image is deployed on a container.
VI. Processes
Execute the app as one or more stateless processes
Look at your application as a stateless process. Imagine the pain maintaining the status for a scalable application (sticky session will hinder true scalability)
So make sure to outsource session management
VII. Port binding
Export services via port binding
“The twelve-factor app is completely self-contained and does not rely on runtime injection of a webserver into the execution environment to create a web-facing service. The web app exports HTTP as a service by binding to a port, and listening to requests coming in on that port.”
https://12factor.net/port-binding
VIII. Concurrency
Scale out via the process model
“The process model truly shines when it comes time to scale out. The share-nothing, horizontally partitionable nature of twelve-factor app processes means that adding more concurrency is a simple and reliable operation. “
https://12factor.net/concurrency
IX. Disposability
Maximize robustness with fast startup and graceful shutdown
“The twelve-factor app’s processes are disposable, meaning they can be started or stopped at a moment’s notice. This facilitates fast elastic scaling, rapid deployment of code or config changes, and robustness of production deploys.”
https://12factor.net/disposability
- Processes should strive to minimize startup time.
- Processes shut down gracefully
X. Dev/prod parity
Keep development, staging, and production as similar as possible
You might have seen issues, where something that was working and tested on a lower environment, suddenly starts showing some erroneous behavior in production. This can be due to some mismatch in terms of tools/ library versions. To avoid such a situation it is recommended to keep all environments as similar as possible.
XI. Logs
Treat logs as event streams
Logs are the lifeline of any application and their importance becomes more with a distributed system (say there is an issue, you need to know where the problem is in a distributed system which might consist of tens of applications). But log handling should not be the responsibility of the code. All logs are streamed out to a specialized system meant to manage logs like Splunk or ELK.
XII. Admin processes
Run admin/management tasks as one-off processes
There can be some one-time maintenance tasks like database migration or backup, report generation, a maintenance script, etc. The idea is to keep these tasks independent of the core application and handled separately.